This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
Why Google’s AI Overviews gets things wrong
When Google announced it was rolling out its artificial intelligence-powered search feature earlier this month, the company promised that “Google will do the googling for you.”The new feature, called AI Overviews, provides brief, AI-generated summaries highlighting key information and links on top of search results.
Unfortunately, AI systems are inherently unreliable. And within days of AI Overviews being released in the US, users quickly shared examples of the feature suggesting that its users add glue to pizza, eat at least one small rock a day, and that former US president Andrew Johnson earned university degrees between 1947 and 2012, despite dying in 1875.
Yesterday, Liz Reid, head of Google Search, announced that the company has been making technical improvements to the system.
But why is AI Overviews returning unreliable, potentially dangerous information in the first place? And what, if anything, can be done to fix it? Read the full story.
—Rhiannon Williams
AI-directed drones could help find lost hikers faster
If a hiker gets lost in the rugged Scottish Highlands, rescue teams sometimes send up a drone to search for clues of the individual’s route. But with vast terrain to cover and limited battery life, picking the right area to search is critical.
Traditionally, expert drone pilots use a combination of intuition and statistical “search theory”—a strategy with roots in World War II–era hunting of German submarines—to prioritize certain search locations over others.
Now researchers want to see if a machine-learning system could do better. Read the full story.
—James O’Donnell
What’s next for bird flu vaccines
In the US, bird flu has now infected cows in nine states, millions of chickens, and—as of last week—a second dairy worker. There’s no indication that the virus has acquired the mutations it would need to jump between humans, but the possibility of another pandemic has health officials on high alert. Last week, they said they are working to get 4.8 million doses of H5N1 bird flu vaccine packaged into vials as a precautionary measure.
The good news is that we’re far more prepared for a bird flu outbreak than we were for covid. We know so much more about influenza than we did about coronaviruses. And we already have hundreds of thousands of doses of a bird flu vaccine sitting in the nation’s stockpile.
This story is from The Checkup, our weekly biotech and health newsletter. Sign up to receive it in your inbox every Thursday.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 Russia, Iran and China used generative AI in covert propaganda campaigns But their efforts weren’t overly successful. (NYT $) + The groups used the generative AI models to write social media posts. (WP $) + NSO Group spyware has been used to hack Russian journalists living abroad. (Bloomberg $) + How generative AI is boosting the spread of disinformation and propaganda. (MIT Technology Review)
2 TikTok is reportedly working on a clone of its recommendation algorithm Splitting its source code could trigger the creation of a US-only version of the app. (Reuters) + TikTok is attempting to convince the US of its independence from China. (The Verge)
3 A man in England has received a personalized cancer vaccine Elliot Pfebve is the first patient to receive the jab as part of a major trial. (The Guardian) + Cancer vaccines are having a renaissance. (MIT Technology Review)
4 Amazon’s drone delivery business has cleared a major hurdle US regulators have approved its drones to fly longer distances. (CNBC)
5 OpenAI has launched a version of ChatGPT for universities ChatGPT Edu is supposed to help institutions deploy AI “responsibly.” (Forbes) + ChatGPT is going to change education, not destroy it. (MIT Technology Review)
6 Chile is fighting back against Big Tech’s data centers Activists aren’t happy with the American giants’ lack of transparency. (Rest of World) + Energy-hungry data centers are quietly moving into cities. (MIT Technology Review)
7 Israel is tracking subatomic particles to map underground areas Archaeologists avoid digging in places with religious significance. (Bloomberg $)
8 Ecuador is in serious trouble Drought and power outages are making daily life increasingly difficult. (Wired $) + Emissions hit a record high in 2023. Blame hydropower. (MIT Technology Review)
9 How to fight the rise of audio deepfakes A wave of new techniques could make it easier to tackle the convincing clips. (IEEE Spectrum) + Here’s what it’s like to come across your nonconsensual AI clone. (404 Media) + An AI startup made a hyperrealistic deepfake of me that’s so good it’s scary. (MIT Technology Review)
10 The James Webb Space Telescope has spotted its most distant galaxy yet The JADES-GS-z14-0 galaxy was captured as it was a mere 290 million years after the Big Bang. (BBC)
Quote of the day
“Despite what Donald Trump thinks, America is not for sale to billionaires, oil and gas executives, or even Elon Musk.”
—James Singer, a spokesperson for the Biden campaign, mocks Trump’s attempts to court Musk and other mega donors to fund his reelection campaign, the Financial Times reports.
The big story
How to fix the internet
October 2023
We’re in a very strange moment for the internet. We all know it’s broken. But there’s a sense that things are about to change. The stranglehold that the big social platforms have had on us for the last decade is weakening.
There’s a sort of common wisdom that the internet is irredeemably bad. That social platforms, hungry to profit off your data, opened a Pandora’s box that cannot be closed.
But the internet has also provided a haven for marginalized groups and a place for support. It offers information at times of crisis. It can connect you with long-lost friends. It can make you laugh.
The internet is worth fighting for because despite all the misery, there’s still so much good to be found there. And yet, fixing online discourse is the definition of a hard problem. But don’t worry. I have an idea. Read the full story.
—Katie Notopoulos
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or tweet ’em at me.)+ It’s peony season! + Forget giant squid—there’s colossal squid living in the depths of the ocean. + Is a long conversation in a film your idea of cinematic perfection, or a drawn-out nightmare? + Here’s how to successfully decompress after a long day at work.
When Google announced it was rolling out its artificial-intelligence-powered search feature earlier this month, the company promised that “Google will do the googling for you.” The new feature, called AI Overviews, provides brief, AI-generated summaries highlighting key information and links on top of search results.
Unfortunately, AI systems are inherently unreliable. Within days of AI Overviews’ release in the US, users were sharing examples of responses that were strange at best. It suggested that users add glue to pizza or eat at least one small rock a day, and that former US president Andrew Johnson earned university degrees between 1947 and 2012, despite dying in 1875.
On Thursday, Liz Reid, head of Google Search, announced that the company has been making technical improvements to the system to make it less likely to generate incorrect answers, including better detection mechanisms for nonsensical queries. It is also limiting the inclusion of satirical, humorous, and user-generated content in responses, since such material could result in misleading advice.
But why is AI Overviews returning unreliable, potentially dangerous information? And what, if anything, can be done to fix it?
How does AI Overviews work?
In order to understand why AI-powered search engines get things wrong, we need to look at how they’ve been optimized to work. We know that AI Overviews uses a new generative AI model in Gemini, Google’s family of large language models (LLMs), that’s been customized for Google Search. That model has been integrated with Google’s core web ranking systems and designed to pull out relevant results from its index of websites.
Most LLMs simply predict the next word (or token) in a sequence, which makes them appear fluent but also leaves them prone to making things up. They have no ground truth to rely on, but instead choose each word purely on the basis of a statistical calculation. That leads to hallucinations. It’s likely that the Gemini model in AI Overviews gets around this by using an AI technique called retrieval-augmented generation (RAG), which allows an LLM to check specific sources outside of the data it’s been trained on, such as certain web pages, says Chirag Shah, a professor at the University of Washington who specializes in online search.
Once a user enters a query, it’s checked against the documents that make up the system’s information sources, and a response is generated. Because the system is able to match the original query to specific parts of web pages, it’s able to cite where it drew its answer from—something normal LLMs cannot do.
One major upside of RAG is that the responses it generates to a user’s queries should be more up to date, more factually accurate, and more relevant than those from a typical model that just generates an answer based on its training data. The technique is often used to try to prevent LLMs from hallucinating. (A Google spokesperson would not confirm whether AI Overviews uses RAG.)
So why does it return bad answers?
But RAG is far from foolproof. In order for an LLM using RAG to come up with a good answer, it has to both retrieve the information correctly and generate the response correctly. A bad answer results when one or both parts of the process fail.
In the case of AI Overviews’ recommendation of a pizza recipe that contains glue—drawing from a joke post on Reddit—it’s likely that the post appeared relevant to the user’s original query about cheese not sticking to pizza, but something went wrong in the retrieval process, says Shah. “Just because it’s relevant doesn’t mean it’s right, and the generation part of the process doesn’t question that,” he says.
Similarly, if a RAG system comes across conflicting information, like a policy handbook and an updated version of the same handbook, it’s unable to work out which version to draw its response from. Instead, it may combine information from both to create a potentially misleading answer.
“The large language model generates fluent language based on the provided sources, but fluent language is not the same as correct information,” says Suzan Verberne, a professor at Leiden University who specializes in natural-language processing.
The more specific a topic is, the higher the chance of misinformation in a large language model’s output, she says, adding: “This is a problem in the medical domain, but also education and science.”
According to the Google spokesperson, in many cases when AI Overviews returns incorrect answers it’s because there’s not a lot of high-quality information available on the web to show for the query—or because the query most closely matches satirical sites or joke posts.
The spokesperson says the vast majority of AI Overviews provide high-quality information and that many of the examples of bad answers were in response to uncommon queries, adding that AI Overviews containing potentially harmful, obscene, or otherwise unacceptable content came up in response to less than one in every 7 million unique queries. Google is continuing to remove AI Overviews on certain queries in accordance with its content policies.
It’s not just about bad training data
Although the pizza glue blunder is a good example of a case where AI Overviews pointed to an unreliable source, the system can also generate misinformation from factually correct sources. Melanie Mitchell, an artificial-intelligence researcher at the Santa Fe Institute in New Mexico, googled “How many Muslim presidents has the US had?’” AI Overviews responded: “The United States has had one Muslim president, Barack Hussein Obama.”
While Barack Obama is not Muslim, making AI Overviews’ response wrong, it drew its information from a chapter in an academic book titled Barack Hussein Obama: America’s First Muslim President?So not only did the AI system miss the entire point of the essay, it interpreted it in the exact opposite of the intended way, says Mitchell. “There’s a few problems here for the AI; one is finding a good source that’s not a joke, but another is interpreting what the source is saying correctly,” she adds. “This is something that AI systems have trouble doing, and it’s important to note that even when it does get a good source, it can still make errors.”
Can the problem be fixed?
Ultimately, we know that AI systems are unreliable, and so long as they are using probability to generate text word by word, hallucination is always going to be a risk. And while AI Overviews is likely to improve as Google tweaks it behind the scenes, we can never be certain it’ll be 100% accurate.
Google has said that it’s adding triggering restrictions for queries where AI Overviews were not proving to be especially helpful and has added additional “triggering refinements” for queries related to health. The company could add a step to the information retrieval process designed to flag a risky query and have the system refuse to generate an answer in these instances, says Verberne. Google doesn’t aim to show AI Overviews for explicit or dangerous topics, or for queries that indicate a vulnerable situation, the company spokesperson says.
Techniques like reinforcement learning from human feedback, which incorporates such feedback into an LLM’s training, can also help improve the quality of its answers.
Similarly, LLMs could be trained specifically for the task of identifying when a question cannot be answered, and it could also be useful to instruct them to carefully assess the quality of a retrieved document before generating an answer, Verbene says: “Proper instruction helps a lot!”
Although Google has added a label to AI Overviews answers reading “Generative AI is experimental,” it should consider making it much clearer that the feature is in beta and emphasizing that it is not ready to provide fully reliable answers, says Shah. “Until it’s no longer beta—which it currently definitely is, and will be for some time— it should be completely optional. It should not be forced on us as part of core search.”
This article first appeared in The Checkup, MIT Technology Review’s weekly biotech newsletter. To receive it in your inbox every Thursday, and read articles like this first, sign up here.
Here in the US, bird flu has now infected cows in nine states, millions of chickens, and—as of last week—a second dairy worker. There’s no indication that the virus has acquired the mutations it would need to jump between humans, but the possibility of another pandemic has health officials on high alert. Last week, they said they are working to get 4.8 million doses of H5N1 bird flu vaccine packaged into vials as a precautionary measure.
The good news is that we’re far more prepared for a bird flu outbreak than we were for covid. We know so much more about influenza than we did about coronaviruses. And we already have hundreds of thousands of doses of a bird flu vaccine sitting in the nation’s stockpile.
The bad news is we would need more than 600 million doses to cover everyone in the US, at two shots per person. And the process we typically use to produce flu vaccines takes months and relies on massive quantities of chicken eggs. Yes, chickens. One of the birds that’s susceptible to avian flu. (Talk about putting all our eggs in one basket. #sorrynotsorry)
This week in The Checkup, let’s look at why we still use a cumbersome, 80-year-old vaccine production process to make flu vaccines—and how we can speed it up.
The idea to grow flu virus in fertilized chicken eggs originated with Frank Macfarlane Burnet, an Australian virologist. In 1936, he discovered that if he bored a tiny hole in the shell of a chicken egg and injected flu virus between the shell and the inner membrane, he could get the virus to replicate.
Even now, we still grow flu virus in much the same way. “I think a lot of it has to do with the infrastructure that’s already there,” says Scott Hensley, an immunologist at the University of Pennsylvania’s Perelman School of Medicine. It’s difficult for companies to pivot.
The process works like this:Health officials provide vaccine manufacturers with a candidate vaccine virus that matches circulating flu strains. That virus is injected into fertilized chicken eggs, where it replicates for several days. The virus is then harvested, killed (for most use cases), purified, and packaged.
Making flu vaccine in eggs has a couple of major drawbacks. For a start, the virus doesn’t always grow well in eggs. So the first step in vaccine development is creating a virus that does. That happens through an adaptation process that can take weeks or even months. This process is particularly tricky for bird flu: Viruses like H5N1 are deadly to birds, so the virus might end up killing the embryo before the egg can produce much virus. To avoid this, scientists have to develop a weakened version of the virus by combining genes from the bird flu virus with genes typically used to produce seasonal flu virus vaccines.
And then there’s the problem of securing enough chickens and eggs. Right now, many egg-based production lines are focused on producing vaccines for seasonal flu. They could switch over to bird flu, but “we don’t have the capacity to do both,” Amesh Adalja, an infectious disease specialist at Johns Hopkins University, told KFF Health News. The US government is so worried about its egg supply that it keeps secret, heavily guarded flocks of chickens peppered throughout the country.
Most of the flu virus used in vaccines is grown in eggs, but there are alternatives. The seasonal flu vaccine Flucelvax, produced by CSL Seqirus, is grown in a cell line derived in the 1950s from the kidney of a cocker spaniel. The virus used in the seasonal flu vaccine FluBlok, made by Protein Sciences, isn’t grown; it’s synthesized. Scientists engineer an insect virus to carry the gene for hemagglutinin, a key component of the flu virus that triggers the human immune system to create antibodies against it. That engineered virus turns insect cells into tiny hemagglutinin production plants.
And then we have mRNA vaccines, which wouldn’t require vaccine manufacturers to grow any virus at all. There aren’t yet any approved mRNA vaccines for influenza, but many companies are fervently working on them, including Pfizer, Moderna, Sanofi, and GSK. “With the covid vaccines and the infrastructure that’s been built for covid, we now have the capacity to ramp up production of mRNA vaccines very quickly,” says Hensley. This week, the Financial Timesreported that the US government will soon close a deal with Moderna to provide tens of millions of dollars to fund a large clinical trial of a bird flu vaccine the company is developing.
There are hints that egg-free vaccines might work better than egg-based vaccines.A CDC study published in January showed that people who received Flucelvax or FluBlok had more robust antibody responses than those who received egg-based flu vaccines. That may be because viruses grown in eggs sometimes acquire mutations that help them grow better in eggs. Those mutations can change the virus so much that the immune response generated by the vaccine doesn’t work as well against the actual flu virus that’s circulating in the population.
Hensley and his colleagues are developing an mRNA vaccine against bird flu. So far they’ve only tested it in animals, but the shot performed well, he claims. “All of our preclinical studies in animals show that these vaccines elicit a much stronger antibody response compared with conventional flu vaccines.”
No one can predict when we might need a pandemic flu vaccine. But just because bird flu hasn’t made the jump to a pandemic doesn’t mean it won’t. “The cattle situation makes me worried,” Hensley says. Humans are in constant contact with cows, he explains. While there have only been a couple of human cases so far, “the fear is that some of those exposures will spark a fire.” Let’s make sure we can extinguish it quickly.
I don’t have to tell you that mRNA vaccines are a big deal. In 2021, MIT Technology Review highlighted them as one of the year’s 10 breakthrough technologies. Antonio Regalado explored their massive potential to transform medicine. Jessica Hamzelou wrote about the other diseases researchers are hoping to tackle.I followed up with a story after two mRNA researchers won a Nobel Prize. And earlier this year I wrote about a new kind of mRNA vaccine that’s self-amplifying, meaning it not only works at lower doses, but also sticks around for longer in the body.
From around the web
Researchers installed a literal window into the brain, allowing for ultrasound imaging that they hope will be a step toward less invasive brain-computer interfaces. (Stat)
People who carry antibodies against the common viruses used to deliver gene therapies can mount a dangerous immune response if they’re re-exposed. That means many people are ineligible for these therapies and others can’t get a second dose. Now researchers are hunting for a solution. (Nature)
More good news about Ozempic. A new study shows that the drug can cut the risk of kidney complications, including death in people with diabetes and chronic kidney disease. (NYT)
Must read: This story, the second in series on the denial of reproductive autonomy for people with sickle-cell disease, examines how the US medical system undermines a woman’s right to choose. (Stat)
If a hiker gets lost in the rugged Scottish Highlands, rescue teams sometimes send up a drone to search for clues of the individual’s route—trampled vegetation, dropped clothing, food wrappers. But with vast terrain to cover and limited battery life, picking the right area to search is critical.
Traditionally, expert drone pilots use a combination of intuition and statistical “search theory”—a strategy with roots in World War II–era hunting of German submarines—to prioritize certain search locations over others. Jan-Hendrik Ewers and a team from the University of Glasgow recently set out to see if a machine-learning system could do better.
Ewers grew up skiing and hiking in the Highlands, giving him a clear idea of the complicated challenges involved in rescue operations there. “There wasn’t much to do growing up, other than spending time outdoors or sitting in front of my computer,” he says. “I ended up doing a lot of both.”
To start, Ewers took data sets of search-and-rescue cases from around the world, which include details such as an individual’s age, whether they were hunting, horseback riding, or hiking, and if they suffered from dementia, along with information about the location where the person was eventually found—by water, buildings, open ground, trees, or roads. He trained an AI model with this data, in addition to geographical data from Scotland. The model runs millions of simulations to reveal the routes a missing person would be most likely to take under the specific circumstances. The result is a probability distribution—a heat map of sorts—indicating the priority search areas.
With this kind of probability map, the team showed that deep learning could be used to design more efficient search paths for drones. In research published last week on arXiv, which has not yet been peer reviewed, the team tested its algorithm against two common search patterns: the “lawn mower,” in which a drone would fly over a target area in a series of simple stripes, and an algorithm similar to Ewers’s but less adept at working with probability distribution maps.
In virtual testing, Ewers’s algorithm beat both of those approaches on two key measures: the distance a drone would have to fly to locate the missing person, and the likelihood that the person was found. While the lawn mower and the existing algorithmic approach found the person 8% of the time and 12% of the time, respectively, Ewers’s approach found them 19% of the time. If it proves successful in real rescue situations, the new system could speed up response times, and save more lives, in scenarios where every minute counts.
“The search-and-rescue domain in Scotland is extremely varied, and also quite dangerous,” Ewers says. Emergencies can arise in thick forests on the Isle of Arran, the steep mountains and slopes around the Cairngorm Plateau, or the faces of Ben Nevis, one of the most revered but dangerous rock climbing destinations in Scotland. “Being able to send up a drone and efficiently search with it could potentially save lives,” he adds.
Search-and-rescue experts say that using deep learning to design more efficient drone routes could help locate missing persons faster in a variety of wilderness areas, depending on how well suited the environment is for drone exploration (it’s harder for drones to explore dense canopy than open brush, for example).
“That approach in the Scottish Highlands certainly sounds like a viable one, particularly in the early stages of search when you’re waiting for other people to show up,” says David Kovar, a director at the US National Association for Search and Rescue in Williamsburg, Virginia, who has used drones for everything from disaster response in California to wilderness search missions in New Hampshire’s White Mountains.
But there are caveats. The success of such a planning algorithm will hinge on how accurate the probability maps are. Overreliance on these maps could mean that drone operators spend too much time searching the wrong areas.
Ewers says a key next step to making the probability maps as accurate as possible will be obtaining more training data. To do that, he hopes to use GPS data from more recent rescue operations to run simulations, essentially helping his model to understand the connections between the location where someone was last seen and where they were ultimately found.
Not all rescue operations contain rich enough data for him to work with, however. “We have this problem in search and rescue where the training data is extremely sparse, and we know from machine learning that we want a lot of high-quality data,” Ewers says. “If an algorithm doesn’t perform better than a human, you are potentially risking someone’s life.”
In the US, for example, drone pilots are required to have a constant line of sight between them and their drone. In Scotland, meanwhile, operators aren’t permitted to be more than 500 meters away from their drone. These rules are meant to prevent accidents, such as a drone falling and endangering people, but in rescue settings such rules severely curtail ground rescuers’ ability to survey for clues.
“Oftentimes we’re facing a regulatory problem rather than a technical problem,” Kovar says. “Drones are capable of doing far more than we’re allowed to use them for.”
Ewers hopes that models like his might one day expand the capabilities of drones even more. For now, he is in conversation with the Police Scotland Air Support Unit to see what it would take to test and deploy his system in real-world settings.
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
The messy quest to replace drugs with electricity
In the early 2010s, electricity seemed poised for a hostile takeover of your doctor’s office. Research into how the nervous system—the highway that carries electrical messages between the brain and the body— controls the immune response was gaining traction.
And that had opened the door to the possibility of hacking into the body’s circuitry and thereby controlling a host of chronic diseases, including rheumatoid arthritis, asthma, and diabetes, as if the immune system were as reprogrammable as a computer.
To do that you’d need a new class of implant: an “electroceutical.” These devices would replace drugs. No more messy side effects. And no more guessing whether a drug would work differently for you and someone else. In the 10 years or so since, around a billion dollars has accreted around the effort. But electroceuticals have still not taken off as hoped.
Now, however, a growing number of researchers are starting to look beyond the nervous system, and experimenting with clever ways to electrically manipulate cells elsewhere in the body, such as the skin.
Their work suggests that this approach could match the early promise of electroceuticals, yielding fast-healing bioelectric bandages, novel approaches to treating autoimmune disorders, new ways of repairing nerve damage, and even better treatments for cancer. Read the full story.
—Sally Adee
Why bigger EVs aren’t always better
SUVs are taking over the world—larger vehicle models made up nearly half of new car sales globally in 2023, a new record for the segment.
There are a lot of reasons to be nervous about the ever-expanding footprint of vehicles, from pedestrian safety and road maintenance concerns to higher greenhouse-gas emissions. But in a way, SUVs also represent a massive opportunity for climate action, since pulling the worst gas-guzzlers off the roads and replacing them with electric versions could be a big step in cutting pollution.
It’s clear that we’re heading toward a future with bigger cars. Here’s what it might mean for the climate, and for our future on the road. Read the full story.
—Casey Crownhart
This story is from The Spark, our weekly climate and energy newsletter. Sign up to receive it in your inbox every Wednesday.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 A pro-Palestinian AI image has been shared millons of times But social media activism critics feel it’s merely performative. (WP $) + The smooth, sanitized picture is inescapable across Instagram and TikTok. (Vox) + It appears to have originated from Malaysia. (The Guardian)
2 OpenAI is struggling to rein in its internal rows Six months after Sam Altman returned as CEO following a coup, divisions remain. (FT $) + A nonprofit created by former Facebook workers is experiencing similar problems. (Wired $)
3 Chinese EV makers are facing a new hurdle in the US A new bill could quadruple import duties on Chinese EVs to 100% (TechCrunch) + Why China’s EV ambitions need virtual power plants. (MIT Technology Review)
4 India’s election wasn’t derailed by deepfakes AI fakery was largely restricted to trolling, rather than malicious interference. (Rest of World) + Meta says AI-generated election content is not happening at a “systemic level” (MIT Technology Review)
5 Extreme weather events are feeding into each other It’s becoming more difficult to separate disasters into standalone events. (Vox) + Our current El Niño climate event is about to make way for La Niña. (The Atlantic $) + Last summer was the hottest in 2,000 years. Here’s how we know. (MIT Technology Review)
6 It’s high time to stop paying cyber ransoms Paying criminals isn’t stopping attacks, experts worry. (Bloomberg $)
7 How programmatic advertising facilitated the spread of misinformation Algorithmically-placed ads are funding shadowing operations across the web. (Wired $)
8 Smart bandages could help to heal wound faster Sensor-embedded dressings could help doctors to monitor ailments remotely. (WSJ $)
9 Move over smartphones—the intelliPhones are coming It’s a lame name for the AI-powered phones of tomorrow. (Insider $)
10 The content creators worth paying attention to Algorithms are no substitution for enthusiastic human curators. (New Yorker $)
Quote of the day
“It’s not about managing your home, it’s about what’s happening. That’s like, ‘Hey, there’s raccoons in my backyard.’”
—Liz Hamren, CEO of smart doorbell company Ring, explains the firm’s pivot away from fighting neighborhood crime and towards keeping tabs on wildlife to Bloomberg.
The big story
House-flipping algorithms are coming to your neighborhood
April 2022
When Michael Maxson found his dream home in Nevada, it was not owned by a person but by a tech company, Zillow. When he went to take a look at the property, however, he discovered it damaged by a huge water leak. Despite offering to handle the costly repairs himself, Maxson discovered that the house had already been sold to another family, at the same price he had offered.
During this time, Zillow lost more than $420 million in three months of erratic house buying and unprofitable sales, leading analysts to question whether the entire tech-driven model is really viable. For the rest of us, a bigger question remains: Does the arrival of Silicon Valley tech point to a better future for housing or an industry disruption to fear? Read the full story.
—Matthew Ponsford
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or tweet ’em at me.)
+ What mathematics can tell us about the formation of animal patterns. + How much pasta is too much pasta? + Here’s how to stretch out your lower back—without risking making it worse. + Over on the Thailand-Malaysia Border, food is an essential signifier of identity.
This article is from The Spark, MIT Technology Review’s weekly climate newsletter. To receive it in your inbox every Wednesday, sign up here.
SUVs are taking over the world—larger vehicle models made up nearly half of new car sales globally in 2023, a new record for the segment.
There are a lot of reasons to be nervous about the ever-expanding footprint of vehicles, from pedestrian safety and road maintenance concerns to higher greenhouse-gas emissions. But in a way, SUVs also represent a massive opportunity for climate action, since pulling the worst gas-guzzlers off the roads and replacing them with electric versions could be a big step in cutting pollution.
It’s clear that we’re heading toward a future with bigger cars. Here’s what it might mean for the climate, and for our future on the road.
SUVs accounted for 48% of global car sales in 2023, according to a new analysis from the International Energy Agency. This is a continuation of a trend toward bigger cars—just a decade ago, SUVs only made up about 20% of new vehicle sales.
Big vehicles mean big emissions numbers. Last year there were more than 360 million SUVs on the roads, and they produced a billion metric tons of carbon dioxide. If SUVs were a country, they’d have the fifth-highest emissions of any nation on the planet—more than Japan. Of all the energy-related emissions growth last year, over 20% can be attributed to SUVs.
There are several factors driving the world’s move toward larger vehicles. Larger cars tend to have higher profit margins, so companies may be more likely to make and push those models. And drivers are willing to jump on the bandwagon. I understand the appeal—I learned to drive in a huge SUV, and being able to stretch out my legs and float several feet above traffic has its perks.
Electric vehicles are very much following the trend, with several companies unveiling larger models in the past few years. Some of these newly released electric SUVs are seeing massive success. The Tesla Model Y, released in 2020, was far and away the most popular EV last year, with over 1.2 million units sold in 2023. The BYD Song (also an SUV) took second place with 630,000 sold.
Globally, SUVs made up nearly 50% of new EV sales in 2023, compared to just under 20% in 2018, according to the IEA’s Global EV Outlook 2024. There’s also been a shift away from small cars (think the size of the Fiat 500) and toward large ones (similar to the BMW 7-series).
And big-car obsession is a global phenomenon. The US is the land of the free and the home of the massive vehicles—SUVs made up 65% of new electric-vehicle sales in the country in 2023. But other major markets aren’t all that far behind: in Europe, the share was 52%, and in China, it was 36%. (You can see the above chart broken down by region from the IEA here.)
So it’s clear that we’re clamoring for bigger cars. Now what?
One way of looking at this whole thing is that SUVs offer up an incredible opportunity for climate action. EVs will reduce emissions over their life span relative to gas-powered versions of the same model, so electrifying the biggest emitters on the roads would have an outsize impact. If all gas-powered and hybrid SUVs sold in 2023 were instead electric vehicles, about 770 million metric tons of carbon dioxide would be avoided over the lifetime of those vehicles, according to the IEA report. That’s equivalent to all of China’s road emissions last year.
I previously wrote a somewhat hesitant defense of large EVs for this reason—electric SUVs aren’t perfect, but they could still help us address climate change. If some drivers are willing to buy an EV but aren’t willing to downsize their cars, then having larger electric options available could be a huge lever for climate action.
But there are several very legitimate reasons why not everyone is welcoming the future of massive cars (even electric ones) with open arms. Larger vehicles are harder on roads, making upkeep more expensive. SUVs and other big vehicles are way more dangerous for pedestrians, too. Vehicles with higher front ends and blunter profiles are 45% more likely to cause fatalities in crashes with pedestrians.
Bigger EVs could also have a huge effect on the amount of mining we’ll need to do to meet demand for metals like lithium, nickel, and cobalt. One 2023 study found that larger vehicles could increase the amount of mining needed more than 50% by 2050, relative to the amount that would be necessary if people drove smaller vehicles. Given that mining is energy intensive and can come with significant environmental harms, it’s not an unreasonable worry.
New technologies could help reduce the mining we need to do for some materials: LFP batteries that don’t contain nickel or cobalt are quickly growing in market share, especially in China, and they could help reduce demand for those metals.
Another potential solution is reducing the demand for bigger cars in the first place. Policies have historically had a hand in pushing people toward larger cars and could help us make a U-turn on car bloat. Some countries, including Norway and France, now charge more in taxes or registration for larger vehicles. Paris recently jacked up parking rates for SUVs.
For now, our vehicles are growing, and if we’re going to have SUVs on the roads, then we should have electric options. But bigger isn’t always better.
Now read the rest of The Spark
Related reading
I’ve defended big EVs in the past—SUVs come with challenges, but electric ones are hands-down better for emissions than gas-guzzlers. Read this 2023 newsletter for more.
The average size of batteries in EVs has steadily ticked up in recent years, as I touched on in this newsletter from last year.
Electric cars are still cars, and smaller, safer EVs, along with more transit options, will be key to hitting our climate goals, Paris Marx argued in this 2022 op-ed.
Keeping up with climate
We might be underestimating how much power transmission lines can carry. Sensors can give grid operators a better sense of capacity based on factors like temperature and wind speed, and it could help projects hook up to the grid faster. (Canary Media)
North America could be in for an active fire season, though it’s likely not going to rise to the level of 2023. (New Scientist)
Climate change is making some types of turbulence more common, and that could spell trouble for flying. Studying how birds move might provide clues about dangerous spots. (BBC)
The perceived slowdown for EVs in the US is looking more like a temporary blip than an ongoing catastrophe. Tesla is something of an outlier with its recent slump—most automakers saw greater than 50% growth in the first quarter of this year. (Bloomberg)
This visualization shows just how dominant China is in the EV supply chain, from mining materials like graphite to manufacturing battery cells. (Cipher News)
Climate change is coming for our summer oysters. The variety that have been bred to be eaten year round are sensitive to extreme heat, making their future rocky. (The Atlantic)
The US has new federal guidelines for carbon offsets. It’s an effort to fix up an industry that studies and reports have consistently shown doesn’t work very well. (New York Times)
The most stubborn myth about heat pumps is that they don’t work in cold weather. Heat pumps are actually more efficient than gas furnaces in cold conditions. (Wired)
In the early 2010s, electricity seemed poised for a hostile takeover of your doctor’s office. Research into how the nervous system controls the immune response was gaining traction. And that had opened the door to the possibility of hacking into the body’s circuitry and thereby controlling a host of chronic diseases, including rheumatoid arthritis, asthma, and diabetes, as if the immune system were as reprogrammable as a computer.
To do that you’d need a new class of implant: an “electroceutical,” formally introduced in an article in Naturein 2013. “What we are doing is developing devices to replace drugs,” coauthor and neurosurgeon Kevin Tracey told Wired UK. These would become a “mainstay of medical treatment.” No more messy side effects. And no more guessing whether a drug would work differently for you and someone else.
There was money behind this vision: the British pharmaceutical giant GlaxoSmithKline announced a $1 million research prize, a $50 million venture fund, and an ambitious program to fund 40 researchers who would identify neural pathways that could control specific diseases. And the company had an aggressive timeline in mind. As one GlaxoSmithKline executive put it, the goal was to have “the first medicine that speaks the electrical language of our body ready for approval by the end of this decade.”
In the 10 years or so since, around a billion dollars has accreted around the effort by way of direct and indirect funding. Some implants developed in that electroceutical push have trickled into clinical trials, and two companies affiliated with GlaxoSmithKline and Tracey are ramping up for splashy announcements later this year. We don’t know much yet about how successful the trials now underway have been. But widespread regulatory approval of the sorts of devices envisioned in 2013—devices that could be applied to a broad range of chronic diseases—is not imminent. Electroceuticals are a long way from fomenting a revolution in medical care.
At the same time, a new area of science has begun to cohere around another way of using electricity to intervene in the body. Instead of focusing only on the nervous system—the highway that carries electrical messages between the brain and the body—a growing number of researchers are finding clever ways to electrically manipulate cells elsewhere in the body, such as skin and kidney cells, more directly than ever before. Their work suggests that this approach could match the early promise of electroceuticals, yielding fast-healing bioelectric bandages, novel approaches to treating autoimmune disorders, new ways of repairing nerve damage, and even better treatments for cancer. However, such ventures have not benefited from investment largesse. Investors tend to understand the relationship between biology and electricity only in the context of the nervous system. “These assumptions come from biases and blind spots that were baked in during 100 years of neuroscience,” says Michael Levin, a bioelectricity researcher at Tufts University.
Electrical implants have already had success in targeting specific problems like epilepsy, sleep apnea, and catastrophic bowel dysfunction. But the broader vision of replacing drugs with nerve-zapping devices, especially ones that alter the immune system, has been slower to materialize. In some cases, perhaps the nervous system is not the best way in. Looking beyond this singular locus of control might open the way for a wider suite of electromedical interventions—especially if the nervous system proves less amenable to hacking than originally advertised.
How it started
GSK’s ambitious electroceutical venture was a response to an increasingly onerous problem: 90% of drugs fall down during the obstacle race through clinical trials. A new drug that does squeak by can cost $2 billion or $3 billion and take 10 to 15 years to bring to market, a galling return on investment. The flaw is in the delivery system. The way we administer healing chemicals hasn’t had much of a conceptual overhaul since the Renaissance physician Paracelsus: ingest or inject. Both approaches have built-in inefficiencies: it takes a long time for the drugs to build up in your system, and they can disperse widely before arriving in diluted form at their target, which may make them useless where they are needed and toxic elsewhere. Tracey and Kristoffer Famm, a coauthor on the Nature article who was then a VP at GlaxoSmithKline, explained on the publicity circuit that electroceuticals would solve these problems—acting more quickly and working only in the precise spot where the intervention was needed. After 500 years, finally, here was a new idea.
Well … new-ish.Electrically stimulating the nervous system had racked up promising successes since the mid-20th century. For example, the symptoms of Parkinson’s disease had been treated via deep brain stimulation, and intractable pain via spinal stimulation. However, these interventions could not be undertaken lightly; the implants needed to be placed in the spine or the brain, a daunting prospect to entertain. In other words, this idea would never be a money spinner.
The vagus nerve runs from the brain through the body
WELLCOME COLLECTION
What got GSK excited was recent evidence that health could be more broadly controlled, and by nerves that were easier to access. By the dawn of the 21st century it had become clear you could tap the nervous system in a way that carried fewer risks and more rewards. That was because of findings suggesting that the peripheral nervous system—essentially, everything but the brain and spine—had much wider influence than previously believed.
The prevailing wisdom had long been that the peripheral nervous system had only one job: sensory awareness of the outside world. This information is ferried to the brain along many little neural tributaries that emerge from the extremities and organs, most of which converge into a single main avenue at the torso: the vagus nerve.
Starting in the 1990s, research by Linda Watkins, a neuroscientist leading a team at the University of Colorado, Boulder, suggested that this main superhighway of the peripheral nervous system was not a one-way street after all. Instead it seemed to carry message traffic in both directions, not just into the brain but from the brain back into all those organs. Furthermore, it appeared that this comms link allows the brain to exert some control over the immune system—for example, stoking a fever in response to an infection.
And unlike the brain or spinal cord, the vagus nerve is comparatively easy to access: its path to and from the brain stem runs close to the surface of the neck, along a big cable on either side. You could just pop an electrode on it—typically on the left branch—and get zapping.
Meddling with the flow of traffic up the vagus nerve in this wayhad successfully treated issues in the brain, specifically epilepsy and treatment-resistant depression (and electrical implants for those applications were approved by the FDA around the turn of the millennium). But the insights from Watkins’s team put the down direction in play.
It was Kevin Tracey who joined all these dots, after which it did not take long for him to become the public face of research on vagus nerve stimulation. During the 2000s, he showed that electrically stimulating the nerve calmed inflammation in animals. This “inflammatory reflex,” as he came to call it, implied that the vagus nerve could act as a switch capable of turning off a wide range of diseases, essentially hacking the immune system. In 2007, while based at what is now called the Feinstein Institutes for Medical Research, in New York, he spun his insights off into a Boston startup called SetPoint Medical. Its aim was to develop devices to flip this switch and bring relief, starting with inflammatory bowel disease and rheumatoid arthritis.
By 2012, a coordinated relationship had developed between GSK, Tracey, and US government agencies. Tracey says that Famm and others contacted him “to help them on that Nature article.” A year later the electroceuticals road map was ready to be presented to the public.
The story the researchers told about the future was elegant and simple. It was illustrated by a tale Tracey recounted frequently on the publicity circuit, of a first-in-human case study SetPoint had coordinated at the University of Amsterdam’s Academic Medical Center. That team had implanted a vagus nerve stimulator in a man suffering from rheumatoid arthritis. The stimulation triggered his spleen to release a chemical called acetylcholine. This in turn told the cells in the spleen to switch off production of inflammatory molecules called cytokines. For this man, the approach worked well enough to let him resume his job, play with his kids, and even take up his old hobbies. In fact, his overenthusiastic resumption of his former activities resulted in a sports injury, as Tracey delighted in recounting for reporters and conferences.
Such case studies opened the money spigot. The combination of a wider range of disease targets and less risky surgical targets was an investor’s love language. Where deep brain stimulation and other invasive implants had been limited to rare, obscure, and catastrophic problems, this new interface with the body promised many more customers: the chronic diseases now on the table are much more prevalent, including not only rheumatoid arthritis but diabetes, asthma, irritable bowel syndrome, lupus, and many other autoimmune disorders. GSK launched an investment arm it dubbed Action Potential Venture Capital Limited, with $50 million in the coffers to invest in the technologies and companies that would turn the futuristic vision of electroceuticals into reality. Its inaugural investment was a $5 million stake in SetPoint.
If you were superstitious, what happened next might have looked like an omen. The word “electroceutical” already belonged to someone else—a company called Ivivi Technologies had trademarked it in 2008. “I am fairly certain we sent them a letter soon after they started that campaign, to alert them of our trademark,” says Sean Hagberg, a cofounder and then chief science officer at the company. Today neither GSK nor SetPoint can officially call its tech “electroceuticals,” and both refer to the implants they are developing as “bioelectronic medicine.” However, this umbrella term encompasses a wide range of other interventions, some quite well established, including brain implants, spine implants, hypoglossal nerve stimulation for sleep apnea (which targets a motor nerve running through the vagus), and other peripheral-nervous-system implants, including those for people with severe gastric disorders.
Kevin Tracey has been one of the leading proponents of using electrical stimulation to target inflammation in the body.
MIKE DENORA VIA WIKIPEDIA
The next problem appeared in short order: how to target the correct nerve. The vagus nerve has roughly 100,000 fibers packed tightly within it, says Kip Ludwig, who was then with the US National Institutes of Health and now co-directs the Wisconsin Institute for Translational Neuroengineering at the University of Wisconsin, Madison. These myriad fibers connect to many different organs, including the larynx and lower airways, and electrical fields are not precise enough to hit a single one without hitting many of its neighbors (as Ludwig puts it, “electric fields [are] really promiscuous”).
This explains why a wholesale zap of the entire bundle had long been associated with unpredictable “on-target effects” and unpleasant “off-target effects,” which is another way of saying it didn’t always work and could carry side effects that ranged from the irritating, like a chronic cough, to the life-altering, including headaches and a shortness of breath that is better described as air hunger. Singling out the fibers that led to the particular organ you were after was hard for another reason, too: the existing maps of the human peripheral nervous system were old and quite limited. Such a low-resolution road map wouldn’t be sufficient to get a signal from the highway all the way to a destination.
In 2014, to remedy this and generally advance the field of peripheral nerve stimulation, the NIH announced a research initiative known as SPARC—Stimulating Peripheral Activity to Relieve Conditions—with the aim of pouring $248 million into research on new ways to exploit the nervous system’s electrical pathways for medicine. “My job,” says Gene Civillico, who managed the program until 2021, “was to do a program related to electroceuticals that used the NIH policy options that were available to us to try to make something catalytic happen.” The idea was to make neural anatomical maps and sort out the consequences of following various paths. After the organs were mapped, Civillico says, the next step was to figure out which nerve circuit would stimulate them, and settle on an access point—“And the access point should be the vagus nerve, because that’s where the most interest is.”
Two years later, as SPARC began to distribute its funds, companies moved forward with plans for the first generation of implants. GSK teamed up with Verily (formerly Google Life Sciences) on a $715 million research initiative they called Galvani Bioelectronics, with Famm at its helm as president. SetPoint, which had relocated to Valencia, California, moved to an expanded location, a campus that had once housed a secret Lockheed R&D facility.
How it’s going
Ten years after electroceuticals entered (and then quickly departed) the lexicon, the SPARC program has yielded important information about the electrical particulars of the peripheral nervous system. Its maps have illuminated nodes that are both surgically attractive and medically relevant. It has funded a global constellation of academic researchers. But its insights will be useful for the next generation of implants, not those in trials today.
Today’s implants, from SetPoint and Galvani, will be in the news later this year. Though SetPoint estimates that an extended study of its phase III clinical trial will conclude in 2027, the primary outcomes will be released this summer, says Ankit Shah, a marketing VP at SetPoint. And while Galvani’s trial will conclude in 2029, Famm says, the company is “coming to an exciting point” and will publish patient data later in 2024.
The results could be interpreted as a referendum on the two companies’ different approaches. Both devices treat rheumatoid arthritis, and both target the immune system via the peripheral nervous system, but that’s where the similarities end. SetPoint’s device uses a clamshell design that cuffs around the vagus nerve at the neck. It stimulates for just one minute, once per day. SetPoint representatives say they have never seen the sorts of side effects that have resulted from using such stimulators to treat epilepsy. But if anyone did experience those described by other researchers—even vomiting and headaches—they might be tolerable if they only lasted a minute.
But why not avoid the vagus nerve entirely? Galvani is using a more precise implant that targets the “end organ” of the spleen. If the vagus nerve can be considered the main highway of the peripheral nervous system, an end organ is essentially a particular organ’s “driveway.” Galvani’s target is the point where the splenic nerve (having split off from a system connected to the vagus highway) meets the spleen.
To zero in on such a specific target, the company has sacrificed ease of access. Its implant, which is about the size of a house key, is laparoscopically injected into the body through the belly button. Famm says if this approach works for rheumatoid arthritis, then it will likely translate for all autoimmune disorders. Highlighting this clinical trial in 2022, he told Nature Reviews: “This is what makes the next 10 years exciting.”
The Galvani device and system targets the splenic nerve.
GALVANI VIA BUSINESSWIRE
Perhaps more so for researchers than for patients, however. Even as Galvani and SetPoint prepare talking points, other SPARC-funded groups are still pondering the sorts of research questions suggesting that the best technological interface with the immune system is still up for debate. At the moment, electroceuticals are in the spotlight, but they have a long way to go, says Vaughan Macefield, a neurophysiologist at Monash University in Australia, whose work is funded by a more recent $21 million SPARC grant: “It’s an elegant idea, [but] there are conflicting views.”
Macefield doesn’t think zapping the entire bundle is a good idea. Many researchers are working on ways to get more selective about which particular fibers of the vagus nerve they stimulate. Some are designing novel electrodes that will penetrate specific fibers rather than clamping around all of them. Others are trying to hit the vagus at deeper points in the abdomen. Indeed, some aren’t sure either electricity or an implant is a necessary ingredient of the “electroceutical.” Instead, they are pivoting from electrical stimulation to ultrasound.
The sheer range of these approaches makes it pretty clear that the electroceutical’s final form is still an open research question. Macefield says we still don’t know the nitty-gritty of how vagus nerve stimulation works.
However, Tracey thinks the variety of approaches being developed doesn’t contravene the merits of the basic idea. How tech companies will make this work in the clinic, he says, is a separate business and IP question: “Can you do it with focused ultrasound? Can you do it with a device implanted with abdominal surgery? Can you do it with a device implanted in the neck? Can you do it with a device implanted in the brain, even? All of these strategies are enabled by the idea of the inflammatory reflex.” Until clinical trial data is in, he says, there’s no point arguing about the best way to manipulate the mechanism—and if one approach fails to work, that is not a referendum on the validity of the inflammatory reflex.
After stepping down from SetPoint’s board to resume a purely consulting role in 2011, Tracey focused on his lab work at the Feinstein Institutes, which he directs, to deepen understanding of this pathway. The research there is wide-ranging. Several researchers under his remit are exploring a type of noninvasive, indirect manipulation called transcutaneous auricular vagus nerve stimulation, which stimulates the skin of the ear with a wearable device. Tracey says it’s a “malapropism” to call this approach vagus nerve stimulation. “It’s just an ear buzzer,” he says. It may stimulate a sensory branch of the vagus nerve, which may engage the inflammatory reflex. “But nobody knows,” he says. Nonetheless, several clinical trials are underway.
SetPoint’s device is cuffed around the vagus nerve within the neck of a patient.
SETPOINT MEDICAL
“These things take time,” Tracey says. “It is extremely difficult to invent and develop a completely revolutionary new thing in medicine. In the history of medicine, anything that was truly new and revolutionary takes between 20 and 40 years from the time it’s invented to the time it’s widely adopted.”
“As the discoverer of this pathway,” he says, “what I want to see is multiple therapies, helping millions of people.” This vision will hinge on bigger trials conducted over many more years. These tend to be about as hard for devices as they are for drugs. Many results that look compelling in early trials disappoint in later rounds—just as for drugs. It will be possible, says Ludwig, “for them to pass a short-duration FDA trial yet still really not be a major improvement over the drug solutions.” Even after FDA approval, should it come, yet more studies will be needed to determine whether the implants are subject to the same issues that plague drugs, including habituation.
This vision of electroceuticals seems to have placed about a billion eggs into the single basket of the peripheral nervous system. In some ways, this makes sense. After all, the received wisdom has it that these nervous signals are the only way to exert electrical control of the other cells in the body. Those other trillions—the skin cells, the immune cells, the stem cells—are beyond the reach of direct electrical intervention.
Except in the past 20 years it’s become abundantly clear thatthey are not.
Other cells speak electricity
At the end of the 19th century, the German physiologist Max Verworn watched as a single-celled marine creature was drawn across the surface of his slide as if captured by a tractor beam. It had been, in a way: under the influence of an electric field, it squidged over to the cathode (the pole that attracts positive charge). Many other types of cells could be coaxed to obey the directional wiles of an electric field, a phenomenon known as galvanotaxis.
But this was too weird for biology, and charlatans already occupied too much of the space in the Venn diagram where electricity met medicine. (The association was formalized in 1910 in the Flexner Report, commissioned to improve the dismal state of American medical schools, which sent electrical medicine into exile along with the likes of homeopathy.) Everyone politely forgot about galvanotaxis until the 1970s and ’80s, when the peculiar behavior resurfaced. Yeast, fungi, bacteria, you name it—they all liked a cathode. “We were pulling every kind of cell along on petri dishes with an electric field,” says Ann Rajnicek of the University of Aberdeen in Scotland, who was among the first group of researchers who tried to discover the mechanism when scientific interest reawakened.
Galvanotaxis would have raised few eyebrows if the behavior had been confined to neurons. Those cells have evolved receptors that sense electric fields; they are a fundamental aspect of the mechanism the nervous system uses to send its information. Indeed, the reason neurons are so amenable to electrical manipulation in the first place is that electric implants hijack a relatively predictable mechanism. Zap a nerve or a muscle and you are forcing it to “speak” a language in which it is already fluent.
Non-excitable cells such as those found in skin and bone don’t share these receptors, but it keeps getting more obvious that they somehow still sense and respond to electric fields.
Why? We keep finding more reasons. Galvanotaxis, for example, is increasingly understood to play a crucial role in wound healing. In every species studied, injury to the skin produces an instant, internally generated electric field, and there’s overwhelming evidence that it guides patch-up cells to the center of the wound to start the rebuilding process. But galvanotaxis is not the only way these cells are led by electricity. During development, immature cells seem to sense the electric properties of their neighbors, which plays a role in their future identity—whether they become neurons, skin cells, fat cells, or bone cells.
Early experiments showed that paramecia on a wet plate will orient themselves in the direction of a cathode.
PUBLIC DOMAIN
Intriguing as this all was, no one had much luck turning such insights into medicine. Even attempts to go after the lowest-hanging fruit—by exploiting galvanotaxis for novel bandages—were for many years at best hit or miss. “When we’ve come upon wounds that are intractable, resistant, and will not heal, and we apply an electric field, only 50% or so of the cases actually show any effect,” says Anthony Guiseppi-Elie, a senior fellow with the American International Institute for Medical Sciences, Engineering, and Innovation.
However, in the past few years, researchers have found ways to make electrical stimulation outside the nervous system less of a coin toss.
That’s down to steady progress in our understanding of how exactly non-neural cells pick up on electric fields, which has helped calm anxieties around the mysticism and the Frankenstein associations that have attended biological responses to electricity.
The first big win came in 2006, with the identification of specific genes in skin cells that get turned on and off by electric fields. When skin is injured, the body’s native electric field orients cells toward the center of the wound, and the physiologist Min Zhao and his colleagues found important signaling pathways that are turned on by this field and mobilized to move cells toward this natural cathode. He also found associated receptors, and other scientists added to the catalogue of changes to genes and gene regulatory networks that get switched on and off under an electric field.
What has become clear since then is that there is no simple mechanism waiting at the end of the rainbow. “There isn’t one single master protein, as far as anybody knows, that regulates responses [to an electric field],” says Daniel Cohen, a bioengineer at Princeton University. “Every cell type has a different cocktail of stuff sticking out of it.”
But recent years have brought good news, in both experimental and applied science. First, the experimental platforms to investigate gene expression are in the middle of a transformation. One advance was unveiled last year by Sara Abasi, Guiseppi-Elie, and their colleagues at Texas A&M and the Houston Methodist Research Institute: their carefully designed research platform kept track of pertinent cellular gene expression profiles and how they change under electric fields—specifically, ones tuned to closely mimic what you find in biology. They found evidence for the activation of two proteins involved in tissue growth along with increased expression of a protein called CD-144, a specific version of what’s known as a cadherin. Cadherins are important physical structures that enable cells to stick to each other, acting like little handshakes between cells. They are crucial to the cells’ ability to act en masse instead of individually.
The other big improvement is in tools that can reveal just how cells work together in the presence of electric fields.
A different kind of electroceutical
A major limit on past experiments was that they tended to test the effects of electrical fields either on single cells or on whole animals. Neither is quite the right scale to offer useful insights, explains Cohen: measuring these dynamics in animals is too “messy,” but in single cells, the dynamics are too artificial to tell you much about how cells behave collectively as they heal a wound. That behavior emerges only at relevant scales, like bird flocks, schools of fish, or road traffic. “The math is identical to describe these types of collective dynamics,” he says.
In 2020, Cohen and his team came up with a solution: an experimental setup that strikes the balance between single cell (tells you next to nothing) and animal (tells you too many things at once). The device, called SCHEEPDOG, can reveal what is going on at the tissue level, which is the relevant scale for investigating wound healing.
It uses two sets of electrodes—a bit the way you might twiddle the dials on an Etch A Sketch—placed in a closed bioreactor, which better approximates how electric fields operate in biology. With this setup, Cohen and his colleagues can precisely tune the electrical environment of tens of thousands of cells at a time to influence their behavior.
In this time-lapse, SCHEEPDOG maneuvers epithelial cells with electric fields.
COHEN ET AL
Their subsequent “healing-on-a-chip” platform yielded an interesting discovery: skin cells’ response to an electric field depends on their maturity. The less mature, the easier they were to control.
The culprit? Those cadherins that Abasi and Guiseppi-Elie had also observed changing under electric fields. In mature cells, these little handshakes had become so strong that a competing electric field, instead of gently guiding the cells, caused them to rip apart. The immature skin cells followed the electric field’s directions without complaint.
After they found a way to dial down the cadherins with an antibody drug, all the cells synchronized. For Cohen, the lesson was that it’s more important to look at the system, and the collective dynamics that govern a behavior like wound healing, than at what is happening in any single cell. “This is really important because many clinical attempts at using electrical stimulation to accelerate wound healing have failed,” says Guiseppi-Elie, and it had never become clear why some worked and others some didn’t.
Cohen’s team is now working to translate these findings into next-generation bioelectric plasters. They are far from alone, and the payoff is more than skin deep. A lot of work is going on, some of it open and some behind closed doors with patents being closely guarded, says Cohen.
At Stanford, the University of Arizona, and Northwestern, researchers are creating smart electric bandages that can be implanted under the skin. They can also monitor the state of the wound in real time, increasing the stimulation if healing is too slow. More challenging, says Rajnicek, are ways to interface with less accessible areas of the body. However, here too new tools are revealing intriguing creative solutions.
Electric fields don’t have to directly changecells’ gene expression to be useful. There is another way their application can be turned to medical benefit. Electric fields evoke reactive oxygen species (ROS) in biological cells. Normally, these charged molecules are a by-product of a cell’s everyday metabolic activities. If you induce them purposefully using an external DC current, however, they can be hijacked to do your bidding.
Starting in 2020, theSwiss bioengineer Martin Fussenegger and an international team of collaborators began to publish investigations into this mechanism to power gene expression. He and his team engineered human kidney cells to be hypersensitive to the induced ROSs in quantities that normal cells couldn’t sense. But when these were generated by DC electrodes, the kidney cells could sense the minute quantities just fine.
Using this instrument, in 2023 they were able to create a tiny, wearable insulin factory. The designer kidney cells were created with a synthetic promoter—an engineered sequence of DNA that can drive expression of a target gene—that reacted to those faint inducedROSs by activating a cascade of genetic changes that opened a tap for insulin production on demand.
Then they packaged this electrogenetic contraption into a wearable device that worked for a month in a living mouse, which had been engineered to be diabetic (Fussenegger says that “others have shown that implanted designer cells can generally be active for over a year”). The designer cells in the wearable are kept alive by algae gelatine but are fed by the mouse’s own vascular system, permitting the exchange of nutrients and protein. The cells can’t get out, but the insulin they secrete can, seeping straight into the mouse’s bloodstream. Ten seconds a day of electrical stimulation delivered via needles connected to three AAA batteries was enough to make the implant perform like a pancreas, returning the mouse’s blood sugar to nondiabetic levels. Given how easy it would be to generalize the mechanism, Fussenegger says, there’s no reason insulin should be the only drug such a device can generate. He is quick to stress that this wearable device is very much in the proof-of-concept stage, but others outside the team are excited about its potential. It could provide a more direct electrical alternative to the solution electroceuticals promised for diabetes.
Escaping neurochauvinism
Before the concerted push around branding electroceuticals, efforts to tap the peripheral nervous system were fragmented and did not share much data. Today, thanks to SPARC, which is winding down, data-sharing resources have been centralized. And money, both direct and indirect, for the electroceuticals project has been lavish. Therapies—especially vagus nerve stimulation—have been the subject of “a steady increase in funding and interest,” says Imran Eba, a partner at GSK’s bioelectronics investment arm Action Potential Venture Capital. Eba estimates that the initial GSK seed of $50 million at Action Potential has grown to about $200 million in assets under management.
Whether you call it bioelectronic medicine or electroceuticals, some researchers would like to see the definition take on a broader remit. “It’s been an extremely neurocentric approach,” says Daniel Cohen.
Neurostimulation has not yet shown success against cancer. Other forms of electrical stimulation, however, have proved surprisingly effective. In one study on glioblastoma, tumor-treating fields offered an electrical version of chemotherapy: an electric field blasts a brain tumor, preferentially killing only cells whose electrical identity marks them as dividing (which cancer cells do, pathologically—but neurons, being fully differentiated, do not). A study recently published in The Lancet Oncology suggests that these fields could also work in lung cancer to boost existing drugs and extend survival.
All of this points to more sophisticated interventions than a zap to a nerve. “The complex things that we need to do in medicine will be about communicating with the collective decision-making and problem-solving of the cells,” says Michael Levin. He has been working to repurpose already-approved drugs so they can be used to target the electrical communication between cells. In a funny twist, he has taken to calling these drugs electroceuticals, which has ruffled some feathers. But he would certainly find support from researchers like Cohen. “I would describe electroceuticals much more broadly as anything that manipulates cellular electrophysiology,” Cohen says.
Even interventions with the nervous system could be helped by expanding our understanding of the ways nerve cells react to electricity beyond action potentials. Kim Gokoffski, a professor of clinical ophthalmology at the University of Southern California, is working with galvanotaxis as a possible means of repairing damage to the optic nerve. In prior experiments that involve regrowing axons—the cables that carry messages out of neurons—these new nerve fibers tend to miss the target they’re meant to rejoin. Existing approaches “are all pushing the gas pedal,” she says, “but no one is controlling the steering wheel.” So her group uses electric fields to guide the regenerating axons into position. In rodent trials, this has worked well enough to partially restore sight.
And yet, Cohen says, “there’s massive social stigma around this that is significantly hampering the entire field.” That stigma has dramatically shaped research direction and funding. For Gokoffski, it has led to difficulties with publishing. She also recounts hearing a senior NIH official refer to her lab’s work on reconnecting optic nerves as “New Age–y.” It was a nasty surprise: “New Age–y has a very bad connotation.”
However, there are signs of more support for work outside the neurocentric model of bioelectric medicine. The US Defense Department funds projects in electrical wound healing (including Gokoffski’s). Action Potential’s original remit—confined to targeting peripheral nerves with electrical stimulation—has expanded. “We have a broader approach now, where energy (in any form, be it electric, electromagnetic, or acoustic) can be directed to regulate neuronal or other cellular activities in the body,” Eba wrote in an email. Three of the companies now in their portfolio focus on areas outside neurostimulation. “While we don’t have any investments targeting wound healing or regenerative medicine specifically, there is no explicit exclusion here for us,” he says.
This suggests that the “social stigma” Cohen described around electrical medicine outside the nervous system is slowly beginning to abate. But if such projects are to really flourish, the field needs to be supported, not just tolerated—perhaps with its own road map and dedicated NIH program. Whether or not bioelectric medicine ends up following anything like the original electroceuticals road map, SPARC ensured a flourishing research community, one that is in hot pursuit of promising alternatives.
The use of electricity outside the nervous system needs a SPARC program of its own. But if history is any guide, first it needs a catchy name. It can’t be “electroceuticals.” And the researchers should definitely check the trademark listings before rolling it out.
For years, cloud technology has demonstrated its ability to cut costs, improve efficiencies, and boost productivity. But today’s organizations are looking to cloud for more than simply operational gains. Faced with an ever-evolving regulatory landscape, a complex business environment, and rapid technological change, organizations are increasingly recognizing cloud’s potential to catalyze business transformation.
Cloud can transform business by making it ready for AI and other emerging technologies. The global consultancy McKinsey projects that a staggering $3 trillion in value could be created by cloud transformations by 2030. Key value drivers range from innovation-driven growth to accelerated product development.
“As applications move to the cloud, more and more opportunities are getting unlocked,” says Vinod Mamtani, vice president and general manager of generative AI services for Oracle Cloud Infrastructure. “For example, the application of AI and generative AI are transforming businesses in deep ways.”
No longer simply a software and infrastructure upgrade, cloud is now a powerful technology capable of accelerating innovation, improving agility, and supporting emerging tools. In order to capitalize on cloud’s competitive advantages, however, businesses must ask for more from their cloud transformations.
Every business operates in its own context, and so a strong cloud solution should have built-in support for industry-specific best practices. And because emerging technology increasingly drives all businesses, an effective cloud platform must be ready for AI and the immense impacts it will have on the way organizations operate and employees work.
An industry-specific approach
The imperative for cloud transformation is evident: In today’s fast-faced business environment, cloud can help organizations enhance innovation, scalability, agility, and speed while simultaneously alleviating the burden on time-strapped IT teams. Yet most organizations have not fully made the leap to cloud. McKinsey, for example, reports a broad mismatch between leading companies’ cloud aspirations and realities—though nearly all organizations say they aspire to run the majority of their applications in the cloud within the decade, the average organization has currently relocated only 15–20% of them.
Cloud solutions that take an industry-specific approach can help companies meet their business needs more easily, making cloud adoption faster, smoother, and more immediately useful. “Cloud requirements can vary significantly across vertical industries due to differences in compliance requirements, data sensitivity, scalability, and specific business objectives,” says Deviprasad Rambhatla, senior vice president and sector head of retail services and transportation at Wipro.
Health-care organizations, for instance, need to manage sensitive patient data while complying with strict regulations such as HIPAA. As a result, cloud solutions for that industry must ensure features such as high availability, disaster recovery capabilities, and continuous access to critical patient information.
Retailers, on the other hand, are more likely to experience seasonal business fluctuations, requiring cloud solutions that allow for greater flexibility. “Cloud solutions allow retailers to scale infrastructure on an up-and-down basis,” says Rambhatla. “Moreover, they’re able to do it on demand, ensuring optimal performance and cost efficiency.”
Cloud-based applications can also be tailored to meet the precise requirements of a particular industry. For retailers, these might include analytics tools that ingest vast volumes of data and generate insights that help the business better understand consumer behavior and anticipate market trends.
Generative AI, like predictive AI before it, has rightly seized the attention of business executives. The technology has the potential to add trillions of dollars to annual global economic activity, and its adoption for business applications is expected to improve the top or bottom lines—or both—at many organizations.
While generative AI offers an impressive and powerful new set of capabilities, its business value is not a given. While some powerful foundational models are open to public use, these do not serve as a differentiator for those looking to get ahead of the competition and unlock AI’s full potential. To gain those advantages, organizations must look to enhance AI models with their own data to create unique business insights and opportunities.
Preparing an organization’s data for AI, however, unlocks a new set of challenges and opportunities. This MIT Technology Review Insights survey report investigates whether companies’ data foundations are ready to garner benefits from generative AI, as well as the challenges of building the necessary data infrastructure for this technology. In doing so, it draws on insights from a survey of 300 C-suite executives and senior technology leaders, as well on in-depth interviews with four leading experts.
Its key findings include the following:
Data integration is the leading priority for AI readiness. In our survey, 82% of C-suite and other senior executives agree that “scaling AI or generative AI use cases to create business value is a top priority for our organization.” The number-one challenge in achieving that AI readiness, survey respondents say, is data integration and pipelines (45%). Asked about challenging aspects of data integration, respondents named four: managing data volume, moving data from on-premises to the cloud, enabling real-time access, and managing changes to data.
Executives are laser-focused on data management challenges—and lasting solutions. Among survey respondents, 83% say that their “organization has identified numerous sources of data that we must bring together in order to enable our AI initiatives.” Though data-dependent technologies of recent decades drove data integration and aggregation programs, these were typically tailored to specific use cases. Now, however, companies are looking for something more scalable and use-case agnostic: 82% of respondents are prioritizing solutions “that will continue to work in the future, regardless of other changes to our data strategy and partners.”
Data governance and security is a top concern for regulated sectors. Data governance and security concerns are the second most common data readiness challenge (cited by 44% of respondents). Respondents from highly regulated sectors were two to three times more likely to cite data governance and security as a concern, and chief data officers (CDOs) say this is a challenge at twice the rate of their C-suite peers. And our experts agree: Data governance and security should be addressed from the beginning of any AI strategy to ensure data is used and accessed properly.
This content was produced by Insights, the custom content arm of MIT Technology Review. It was not written by MIT Technology Review’s editorial staff.
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
Quartz, cobalt, and the waste we leave behind
It is easy to convince ourselves that we now live in a dematerialized ethereal world, ruled by digital startups, artificial intelligence, and financial services.
Yet there is little evidence that we have decoupled our economy from its churning hunger for resources. We are still reliant on the products of geological processes like coal and quartz, a mineral that’s a rich source of the silicon used to build computer chips, to power our world.
Three recent books aim to reconnect readers with the physical reality that underpins the global economy. Each one fills in dark secrets about the places, processes, and lived realities that make the economy tick, and reveals just how tragic a toll the materials we rely on take for humans and the environment. Read the full story. —Matthew Ponsford
The story is from the current print issue of MIT Technology Review, which is on the theme of Build. If you don’t already, subscribe now to receive future copies once they land.
If you’re interested in the minerals powering our economy, why not take a look at my colleague James Temple’s pieces about how a US town is being torn apart as communities clash over plans to open a nickel mine—and how that mine could unlock billions in EV subsidies.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 Blacklisted Chinese firms are rebranding as American In a bid to swerve the Biden administration’s crackdown on national security concerns. (WSJ $)+ The US has sanctioned three Chinese nationals over their links to a botnet. (Ars Technica)
2 More than half of cars sold last year were SUVs The large vehicles are major contributors to the climate crisis. (The Guardian) + Three frequently asked questions about EVs, answered. (MIT Technology Review)
3 A record number of electrodes have been placed on a human brain The more electrodes, the higher the resolution for mapping brain activity. (Ars Technica) + Beyond Neuralink: Meet the other companies developing brain-computer interfaces. (MIT Technology Review)
4 A former FTX executive has been sentenced to 7.5 years in prison Ryan Salame had been hoping for a maximum of 18 months. (CoinDesk)
5 Food delivery apps are hemorrhaging money The four major platforms are locked in intense competition for diners. (FT $)
6 Saudi Arabia is going all in on building solar farms It’s looking beyond its oil empire to invest in other promising forms of energy. (NYT $) + The world is finally spending more on solar than oil production. (MIT Technology Review)
7 Clouds are a climate mystery Experts are trying to integrate them into climate models—but it’s tough work. (The Atlantic $) + ‘Bog physics’ could work out how much carbon is stored in peat bogs. (Quanta Magazine)
8 An 11-year old crypto mystery has finally been solved To crack into a $3 million fortune. (Wired $)
9AI models are pretty good at spotting bugs in software The problem is, they’re also prone to making up new flaws entirely. (New Scientist $) + How AI assistants are already changing the way code gets made. (MIT Technology Review)
10 Beware promises made by airmiles influencers While some of their advice is sound, it pays to play the long game. (WP $)
Quote of the day
“We learned about ChatGPT on Twitter.”
—Helen Toner, a former OpenAI board member, explains how the company’s board was not informed in advance about the release of its blockbuster AI system in November 2022, the Verge reports.
The big story
Generative AI is changing everything. But what’s left when the hype is gone?
December 2022
It was clear that OpenAI was on to something. In late 2021, a small team of researchers was playing around with a new version of OpenAI’s text-to-image model, DALL-E, an AI that converts short written descriptions into pictures: a fox painted by Van Gogh, perhaps, or a corgi made of pizza. Now they just had to figure out what to do with it.
Nobody could have predicted just how big a splash this product was going to make. The rapid release of other generative models has inspired hundreds of newspaper headlines and magazine covers, filled social media with memes, kicked a hype machine into overdrive—and set off an intense backlash from creators.
The exciting truth is, we don’t really know what’s coming next. While creative industries will feel the impact first, this tech will give creative superpowers to everybody. Read the full story.
—Will Douglas Heaven
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or tweet ’em at me.)
+ These baby tiger cubs are just too cute. + Meet me at El Califa de León, the world’s first taquería to receive a Michelin star. + This feather sounds like a bargain, frankly. + Did you know that Sean Connery was only 12 years older than Harrison Ford when he played his father in Indiana Jones and the Last Crusade?
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
How the quest to type Chinese on a QWERTY keyboard created autocomplete
—This is an excerpt from The Chinese Computer: A Global History of the Information Age by Thomas S. Mullaney, published on May 28 by The MIT Press. It has been lightly edited.
When a young Chinese man sat down at his QWERTY keyboard in 2013 and rattled off an enigmatic string of letters and numbers, his forty-four keystrokes marked the first steps in a process known as “input” or shuru.
Shuru is the act of getting Chinese characters to appear on a computer monitor or other digital device using a QWERTY keyboard or trackpad.
The young man, Huang Zhenyu, was one of around 60 contestants in the 2013 National Chinese Characters Typing Competition. His keyboard did not permit him to enter these characters directly, however, and so he entered the quasi-gibberish string of letters and numbers instead: ymiw2klt4pwyy1wdy6…
But Zhenyu’s prizewinning performance wasn’t solely noteworthy for his impressive typing speed—one of the fastest ever recorded. It was also premised on the same kind of “additional steps” as the first Chinese computer in history that led to the discovery of autocompletion. Read the rest of the excerpt here.
If you’re interested in tech in China, why not check out some of our China reporter Zeyi Yang’s recent reporting (and subscribe to his weekly newsletter China Report!)
+ GPT-4o’s Chinese token-training data is polluted by spam and porn websites. The problem, which is likely due to inadequate data cleaning, could lead to hallucinations, poor performance, and misuse. Read the full story.
+ Deepfakes of your dead loved ones are a booming Chinese business. People are seeking help from AI-generated avatars to process their grief after a family member passes away. Read the full story.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 Election officials want to pre-bunk harmful online campaigns It’s a bid to prevent political hoaxes from ever getting off the ground. (WP $) + Fake news verification tools are failing in India. (Rest of World) + Three technology trends shaping 2024’s elections. (MIT Technology Review)
2OpenAI has started training the successor to GPT-4 Just weeks after it revealed an updated version, GPT-4o. (NYT $) + OpenAI’s new GPT-4o lets people interact using voice or video in the same model. (MIT Technology Review)
3 China is bolstering its national semiconductor fund To the tune of $48 billion. (WSJ $) + It’s the third round of the country’s native chip funding program. (FT $) + What’s next in chips. (MIT Technology Review)
4 Nuclear plants are extremely expensive to build The US needs to learn how to cut costs without cutting corners. (The Atlantic $) + How to reopen a nuclear power plant. (MIT Technology Review)
5 Laser systems could be the best line of defense against military drones The Pentagon is investing in BlueHalo’s AI-powered laser technology. (Insider $) + The US military is also pumping money into Palmer Luckey’s Anduril. (Wired $) + Inside the messy ethics of making war with machines. (MIT Technology Review)
6 Klarna’s marketing campaigns are the product of generative AI The fintech firm claims the technology will save it $10 million a year. (Reuters)
7 The US has an EV charging problem Would-be car buyers are still nervous about investing in EVs. (Wired $) + Micro-EVs could offer one solution. (Ars Technica) + Toyota has unveiled new engines compatible with alternative fuels. (Reuters)
8 Good luck betting on anything that’s not sports in the US The outcome of a major election, for example. (Vox) + How mobile money supercharged Kenya’s sports betting addiction. (MIT Technology Review)
9 Perfectionist parents are Facetuning their children It goes without saying: don’t do this. (NY Mag $)
10 Why a movie version of The Sims never got off the ground The beloved video game would make for a seriously weird cinema spectacle. (The Guardian)
Quote of the day
“Once materialism starts spreading, it can have a bad influence on teenagers.”
—Chinese state media Beijing News explains why China has started cracking down on luxurious influencers known for their ostentatious displays of wealth, the Financial Times reports.
The big story
Recapturing early internet whimsy with HTML
December 2023
Websites weren’t always slick digital experiences.
There was a time when surfing the web involved opening tabs that played music against your will and sifting through walls of text on a colored background. In the 2000s, before Squarespace and social media, websites were manifestations of individuality—built from scratch using HTML, by users who had some knowledge of code.
Scattered across the web are communities of programmers working to revive this seemingly outdated approach. And the movement is anything but a superficial appeal to retro aesthetics—it’s about celebrating the human touch in digital experiences. Read the full story.
—Tiffany Ng
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or tweet ’em at me.)
This is an excerpt from The Chinese Computer: A Global History of the Information Age by Thomas S. Mullaney, published on May 28 by The MIT Press. It has been lightly edited.
ymiw2
klt4
pwyy1
wdy6
o1
dfb2
wdv2
fypw3
uet5
dm2
dlu1 …
A young Chinese man sat down at his QWERTY keyboard and rattled off an enigmatic string of letters and numbers.
Was it code? Child’s play? Confusion? It was Chinese.
The beginning of Chinese, at least. These 44 keystrokes marked the first steps in a process known as “input” or shuru: the act of getting Chinese characters to appear on a computer monitor or other digital device using a QWERTY keyboard or trackpad.
Stills taken from a 2013 Chinese input competition screencast.
COURTESY OF MIT PRESS
Across all computational and digital media, Chinese text entry relies on software programs known as “input method editors”—better known as “IMEs” or simply “input methods” (shurufa). IMEs are a form of “middleware,” so named because they operate in between the hardware of the user’s device and the software of its program or application. Whether a person is composing a Chinese document in Microsoft Word, searching the web, sending text messages, or otherwise, an IME is always at work, intercepting all of the user’s keystrokes and trying to figure out which Chinese characters the user wants to produce. Input, simply put, is the way ymiw2klt4pwyy … becomes a string of Chinese characters.
IMEs are restless creatures. From the moment a key is depressed or a stroke swiped, they set off on a dynamic, iterative process, snatching up user-inputted data and searching computer memory for potential Chinese character matches. The most popular IMEs these days are based on Chinese phonetics—that is, they use the letters of the Latin alphabet to describe the sound of Chinese characters, with mainland Chinese operators using the country’s official Romanization system, Hanyu pinyin.
Example of Chinese Input Method Editor pop-up menu (抄袭 / “plagiarism”)
COURTESY OF MIT PRESS
This young man was Huang Zhenyu (also known by his nom de guerre, Yu Shi). He was one of around 60 contestants that day, each wearing a bright red shoulder sash—as in a ticker-tape parade of old, or a beauty pageant. “Love Chinese Characters” (Ai Hanzi) was emblazoned in vivid golden yellow on a poster at the front of the hall. The contestants’ task was to transcribe a speech by outgoing Chinese president Hu Jintao, as quickly and as accurately as they could. “Hold High the Great Banner of Socialism with Chinese Characteristics,” it began, or in the original: 高举中国特色社会主义伟大旗帜为夺取全面建设小康社会新胜利而奋斗. Huang’s QWERTY keyboard did not permit him to enter these characters directly, however, and so he entered the quasi-gibberish string of letters and numbers instead: ymiw2klt4pwyy1wdy6 …
With these four dozen keystrokes, Huang was well on his way, not only to winning the 2013 National Chinese Characters Typing Competition, but also to clocking one of the fastest typing speeds ever recorded, anywhere in the world.
ymiw2klt4pwyy1wdy6 … is not the same as 高举中国特色社会主义 … The keys that Huang actually depressed on his QWERTY keyboard—his “primary transcript,” as we could call it—were completely different from the symbols that ultimately appeared on his computer screen, namely the “secondary transcript” of Hu Jintao’s speech. This is true for every one of the world’s billion-plus Sinophone computer users. In Chinese computing, what you type is never what you get.
For readers accustomed to English-language word processing and computing, this should come as a surprise. For example, were you to compare the paragraph you’re reading right now against a key log showing exactly which buttons I depressed to produce it, the exercise would be unenlightening (to put it mildly). “F-o-r-_-r-e-a-d-e-r-s-_-a-c-c-u-s-t-o-m-e-d-_t-o-_-E-n-g-l-i-s-h … ” it would read (forgiving any typos or edits). In English-language typewriting and computer input, a typist’s primary and secondary transcripts are, in principle, identical. The symbols on the keys and the symbols on the screen are the same.
Not so for Chinese computing. When inputting Chinese, the symbols a person sees on a QWERTY keyboard are always different from the symbols that ultimately appear on the monitor or on paper. Every single computer and new media user in the Sinophone world—no matter if they are blazing-fast or molasses-slow—uses their device in exactly the same way as Huang Zhenyu, constantly engaged in this iterative process of criteria-candidacy-confirmation, using one IME or another. Not some Chinese-speaking users, mind you, but all. This is the first and most basic feature of Chinese computing: Chinese human-computer interaction (HCI) requires users to operate entirely in code all the time.
If Huang Zhenyu’s mastery of a complex alphanumeric code weren’t impressive enough, consider the staggering speed of his performance. He transcribed the first 31 Chinese characters of Hu Jintao’s speech in roughly five seconds, for an extrapolated speed of 372 Chinese characters per minute. By the close of the grueling 20-minute contest, one extending over thousands of characters, he crossed the finish line with an almost unbelievable speed of 221.9 characters per minute.
That’s 3.7 Chinese characters every second.
In the context of English, Huang’s opening five seconds would have been the equivalent of around 375 English words per minute, with his overall competition speed easily surpassing 200 WPM—a blistering pace unmatched by anyone in the Anglophone world (using QWERTY, at least). In 1985, Barbara Blackburn achieved a Guinness Book of World Records–verified performance of 170 English words per minute (on a typewriter, no less). Speed demon Sean Wrona later bested Blackburn’s score with a performance of 174 WPM (on a computer keyboard, it should be noted). As impressive as these milestones are, the fact remains: had Huang’s performance taken place in the Anglophone world, it would be his name enshrined in the Guinness Book of World Records as the new benchmark to beat.
Huang’s speed carried special historical significance as well.
For a person living between the years 1850 and 1950—the period examined in the book The Chinese Typewriter—the idea of producing Chinese by mechanical means at a rate of over 200 characters per minute would have been virtually unimaginable. Throughout the history of Chinese telegraphy, dating back to the 1870s, operators maxed out at perhaps a few dozen characters per minute. In the heyday of mechanical Chinese typewriting, from the 1920s to the 1970s, the fastest speeds on record were just shy of 80 characters per minute (with the majority of typists operating at far slower rates). When it came to modern information technologies, that is to say, Chinese was consistently one of the slowest writing systems in the world.
What changed? How did a script so long disparaged as cumbersome and helplessly complex suddenly rival—exceed, even—computational typing speeds clocked in other parts of the world? Even if we accept that Chinese computer users are somehow able to engage in “real time” coding, shouldn’t Chinese IMEs result in a lower overall “ceiling” for Chinese text processing as compared with English? Chinese computer users have to jump through so many more hoops, after all, over the course of a cumbersome, multistep process: the IME has to intercept a user’s keystrokes, search in memory for a match, present potential candidates, and wait for the user’s confirmation. Meanwhile, English-language computer users need only depress whichever key they wish to see printed on screen. What could be simpler than the “immediacy” of “Q equals Q,” “W equals W,” and so on?
COURTESY OF TOM MULLANEY
To unravel this seeming paradox, we will examine the first Chinese computer ever designed: the Sinotype, also known as the Ideographic Composing Machine. Debuted in 1959 by MIT professor Samuel Hawks Caldwell and the Graphic Arts Research Foundation, this machine featured a QWERTY keyboard, which the operator used to input—not the phonetic values of Chinese characters—but the brushstrokes out of which Chinese characters are composed. The objective of Sinotype was not to “build up” Chinese characters on the page, though, the way a user builds up English words through the successive addition of letters. Instead, each stroke “spelling” served as an electronic address that Sinotype’s logical circuit used to retrieve a Chinese character from memory. In other words, the first Chinese computer in history was premised on the same kind of “additional steps” as seen in Huang Zhenyu’s prizewinning 2013 performance.
During Caldwell’s research, he discovered unexpected benefits of all these additional steps—benefits entirely unheard of in the context of Anglophone human-machine interaction at that time. The Sinotype, he found, needed far fewer keystrokes to find a Chinese character in memory than to compose one through conventional means of inscription. By way of analogy, to “spell” a nine-letter word like “crocodile” (c-r-o-c-o-d-i-l-e) took far more time than to retrieve that same word from memory (“c-r-o-c-o-d” would be enough for a computer to make an unambiguous match, after all, given the absence of other words with similar or identical spellings). Caldwell called his discovery “minimum spelling,” making it a core part of the first Chinese computer ever built.
Today, we know this technique by a different name: “autocompletion,” a strategy of human-computer interaction in which additional layers of mediation result in faster textual input than the “unmediated” act of typing. Decades before its rediscovery in the Anglophone world, then, autocompletion was first invented in the arena of Chinese computing.
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
That viral video showing a head transplant is a fake. But it might be real someday.
An animated video posted this week has a voice-over that sounds like a late-night TV ad, but the pitch is straight out of the far future. The arms of an octopus-like robotic surgeon swirl, swiftly removing the head of a dying man and placing it onto a young, healthy body.
This is BrainBridge, the animated video claims—“the world’s first revolutionary concept for a head transplant machine, which uses state-of-the-art robotics and artificial intelligence to conduct complete head and face transplantation.”
BrainBridge is not a real company—it’s not incorporated anywhere. Yet it’s not merely a provocative work of art. This video is better understood as the first public billboard for a hugely controversial scheme to defeat death that’s recently been gaining attention among some life-extension proponents and entrepreneurs. Read the full story.
—Antonio Regalado
Noise-canceling headphones use AI to let a single voice through
Modern life is noisy. If you don’t like it, noise-canceling headphones can reduce the sounds in your environment. But they muffle sounds indiscriminately, so you can easily end up missing something you actually want to hear.
A new prototype AI system for such headphones aims to solve this. Called Target Speech Hearing, the system gives users the ability to select a person whose voice will remain audible even when all other sounds are canceled out.
Although the technology is currently a proof of concept, its creators say they are in talks to embed it in popular brands of noise-canceling earbuds and are also working to make it available for hearing aids. Read the full story.
—Rhiannon Williams
Splashy breakthroughs are exciting, but people with spinal cord injuries need more
—Cassandra Willyard
This week, I wrote about an external stimulator that delivers electrical pulses to the spine to help improve hand and arm function in people who are paralyzed. This isn’t a cure. In many cases the gains were relatively modest.
The study didn’t garner as much media attention as previous, much smaller studies that focused on helping people with paralysis walk. Tech that allows people to type slightly faster or put their hair in a ponytail unaided just doesn’t have the same allure.
For the people who have spinal cord injuries, however, incremental gains can have a huge impact on quality of life. So who does this tech really serve? Read the full story.
This story is from The Checkup, our weekly health and biotech newsletter. Sign up to receive it in your inbox every Thursday.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 Google’s AI search is advising people to put glue on pizza These tools clearly aren’t ready to provide billions of users with accurate answers. (The Verge) + That $60 million Google paid Reddit for its data sure looks questionable. (404 Media) + But who’s legally responsible here? (Vox) + Why you shouldn’t trust AI search engines. (MIT Technology Review)
2 Russia is increasingly interfering with Ukraine’s Starlink service It’s disrupting Ukraine’s ability to collect intelligence and conduct drone attacks. (NYT $)
3 Taiwan is prepared to shut down its chipmaking machines if China invades China is currently circling the island on military exercises. (Bloomberg $) + Meanwhile, China’s PC makers are on the up. (FT $) + What’s next in chips. (MIT Technology Review)
4 X is planning on hiding users’ likes Elon Musk wants to encourage users to like ‘edgy’ content without fear. (Insider $)
5 The scammer who cloned Joe Biden’s voice could be fined $6 million Regulators want to make it clear that political AI manipulation will not be tolerated. (TechCrunch) + He’s due to appear in court next month. (Reuters) + Meta says AI-generated election content is not happening at a “systemic level.” (MIT Technology Review)
6 NSO Group’s former CEO is staging a comeback Shalev Huloi resigned after the US blacklisted the company. (The Intercept)
7 Rivers in Alaska are running orange It’s highly likely that climate change is to blame. (WP $) + It’s looking unlikely that we’re going to limit global warming to 1.5°C. (New Scientist $)
8 We’re learning more about one of the world’s rarest elements Promethium is extremely radioactive, and extremely unstable. (New Scientist $)
9 Children can’t really become music lovers without a phone Without cassette players or CDs, streaming seems the only option.(The Guardian)
10 AI art will always look cheap It’s no substitute for the real deal. (Vox) + This artist is dominating AI-generated art. And he’s not happy about it. (MIT Technology Review)
Quote of the day
“Naming space as a warfighting domain was kind of forbidden, but that’s changed.”
—Air Force General Charles “CQ” Brown explains how the US is preparing to fight adversaries in space, Ars Technica reports.
The big story
How Facebook got addicted to spreading misinformation
March 2021
When the Cambridge Analytica scandal broke in March 2018, it would kick off Facebook’s largest publicity crisis to date. It compounded fears that the algorithms that determine what people see were amplifying fake news and hate speech, and prompted the company to start a team with a directive that was a little vague: to examine the societal impact of the company’s algorithms.
Joaquin Quiñonero Candela was a natural pick to head it up. In his six years at Facebook, he’d created some of the first algorithms for targeting users with content precisely tailored to their interests, and then he’d diffused those algorithms across the company. Now his mandate would be to make them less harmful. However, his hands were tied, and the drive to make money came first. Read the full story.
—Karen Hao
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or tweet ’em at me.)
+ Zillow is the wild west of home listings. This Twitter (sorry, X) account collates some of the best. + COUSIN! We love you, Ebon Moss-Bachrach! + Gimme all the potato salad. + Much sad: rest in power Kabosu, the beautiful shiba inu whose tentative face launched a thousand memes.
This article first appeared in The Checkup, MIT Technology Review’s weekly biotech newsletter. To receive it in your inbox every Thursday, and read articles like this first, sign up here.
The study didn’t garner as much media attention as previous, much smaller studies that focused on helping people with paralysis walk. Tech that allows people to type slightly faster or put their hair in a ponytail unaided just doesn’t have the same allure. “The image of a paralyzed person getting up and walking is almost biblical,” Charles Liu, director of the Neurorestoration Center at the University of Southern California, once told a reporter.
For the people who have spinal cord injuries, however, incremental gains can have a huge impact on quality of life.
So today in The Checkup, let’s talk about this tech and who it serves.
In 2004, Kim Anderson-Erisman, a researcher at Case Western Reserve University, who also happens to be paralyzed, surveyed more than 600 people with spinal cord injuries. Wanting to better understand their priorities, she asked them to consider seven different functions—everything from hand and arm mobility to bowel and bladder function to sexual function. She asked respondents to rank these functions according to how big an impact recovery would have on their quality of life.
Walking was one of the functions, but it wasn’t the top priority for most people. Most quadriplegics put hand and arm function at the top of the list. For paraplegics, meanwhile, the top priority was sexual function. I interviewed Anderson-Erisman for a story I wrote in 2019 about research on implantable stimulators as a way to help people with spinal cord injuries walk. For many people, “not being able to walk is the easy part of spinal cord injury,” she told me. “[If] you don’t have enough upper-extremity strength or ability to take care of yourself independently, that’s a bigger problem than not being able to walk.”
One of the research groups I focused on was at the University of Louisville. When I visited in 2019, the team had recently made the news because two people with spinal cord injuries in one of their studies had regained the ability to walk, thanks to an implanted stimulator. “Experimental device helps paralyzed man walk the length of four football fields,” one headline had trumpeted.
But when I visited one of those participants, Jeff Marquis, in his condo in Louisville, I learned that walking was something he could only do in the lab. To walk he needed to hold onto parallel bars supported by other people and wear a harness to catch him if he fell. Even if he had extra help at home, there wasn’t enough room for the apparatus. Instead, he gets around his condo the same way he gets around outside his condo: in a wheelchair. Marquis does stand at home, but even that requires a bulky frame. And the standing he does is only for therapy. “I mostly just watch TV while I’m doing that,” he said.
That’s not to say the tech has been useless. The implant helped Marquis gain some balance, stamina, and trunk stability. “Trunk stability is kind of underrated in how much easier that makes every other activity I do,” he told me. “That’s the biggest thing that stays with me when I have [the stimulator] turned off.”
What’s exciting to me about this latest study is that the tech gave the participants skills they could use beyond the lab. And because the stimulator is external, it is likely to be more accessible and vastly cheaper. Yes, the newly enabled movements are small, but if you listen to the palpable excitement of one study participant as he demonstrates how he can move a small ball into a cup, you’ll appreciate that incremental gains are far from insignificant. That’s according to Melanie Reid, one of the participants in the latest trial, who spoke at a press conference last week. “There [are] no miracles in spinal injury, but tiny gains can be life-changing.”
Now read the rest of The Checkup
Read more from MIT Technology Review’s archive
In 2017, we hailed as a breakthrough technology electronic interfaces designed to reverse paralysis by reconnecting the brain and body. Antonio Regalado has the story.
An implanted stimulator changed John Mumford’s life, allowing him to once again grasp objects after a spinal cord injury left him paralyzed. But when the company that made the device folded, Mumford was left with few options for keeping the device running. “Limp limbs can be reanimated by technology, but they can be quieted again by basic market economics,” wrote Brian Bergstein in 2015.
In 2014, Courtney Humphries covered some of the rat research that laid the foundation for the technological developments that have allowed paralyzed people to walk.
From around the web
Lots of bird flu news this week. A second person in the US has tested positive for the illness after working with infected livestock. (NBC)
The livestock industry, which depends on shipping tens of millions of live animals, provides some ideal conditions for the spread of pathogens, including bird flu. (NYT)
Long read: How the death of a nine-year-old boy in Cambodia triggered a global H5N1 alert. (NYT)
You’ve heard about tracking viruses via wastewater. H5N1 is the first one we’re tracking via store-bought milk. (STAT)
The first organ transplants from pigs to humans have not ended well, but scientists are learning valuable lessons about what they need to do better. (Nature)
Another long read that’s worth your time: an inside look at just how long 3M knew about the pervasiveness of “forever chemicals.” (New Yorker)
An animated video posted this week has a voice-over that sounds like a late-night TV ad, but the pitch is straight out of the far future. The arms of an octopus-like robotic surgeon swirl, swiftly removing the head of a dying man and placing it onto a young, healthy body.
This is BrainBridge, the animated video claims—“the world’s first revolutionary concept for a head transplant machine, which uses state-of-the-art robotics and artificial intelligence to conduct complete head and face transplantation.”
First posted on Tuesday, the video has millions of views, more than 24,000 comments on Facebook, and a content warning on TikTok for its grisly depictions of severed heads. A slick BrainBridge website has several job postings, including one for a “neuroscience team leader” and another for a “government relations adviser.” It is all convincing enough for the New York Post to announce that BrainBridge is “a biomedical engineering startup” and that “the company” plans a surgery within eight years.
We can report that BrainBridge is not a real company—it’s not incorporated anywhere. The video was made by Hashem Al-Ghaili, a Yemeni science communicator and film director who in 2022 made a viral video called “EctoLife,” about artificial wombs, that also left journalists scrambling to determine if it was real or not.
Yet BrainBridge is not merely a provocative work of art. This video is better understood as a public billboard for a hugely controversial scheme to defeat death that’s recently been gaining attention among some life-extension proponents and entrepreneurs.
“It’s about recruiting newcomers to join the project,” says Al-Ghaili.
This morning, Al-Ghaili, who lives in Dubai, was up at 5 a.m., tracking the video as its viewership ballooned around social media. “I am monitoring its progress,” he says, but he insists he didn’t make the film for clicks: “Being viral is not the goal. I can be viral anytime. It’s pushing boundaries and testing feasibility.”
The video project was bankrolled in part by Alex Zhavoronkov, the founder of Insilico Medicine, a large AI drug discovery company, who is also a prominent figure in anti-aging research. After Zhavoronkov posted the video on his LinkedIn account, commenters noticed that it is his face on the two bodies shown in the video.
“I can confirm I helped design and fund a few things,” Zhavoronkov told MIT Technology Review in a WhatsApp message, in which he also claimed that “some important and famous people are supporting [it] financially.”
Zhavoronkov declined to name these individuals. He also didn’t respond when asked if the job ads—whose cookie-cutter descriptions of qualifications and responsibilities appear to have been written by an AI—are real roles or make-believe positions.
Aging bypass
What is certain is that head transplantation—or body transplant, as some prefer to call it—is a subject of growing, if speculative, interest in longevity circles, the kind inhabited by biohackers, techno-anarchists, and others on the fringes of biotechnology and the startup scene and who form the most dedicated cadre of extreme life-extensionists.
Many proponents of longer life spans will admit things don’t look good. Anti-aging medicine so far hasn’t achieved any breakthroughs. In fact, as research advances into the molecular details, the problem of death only looks more and more complicated. As we age, our billions of cells gradually succumb to the irreversible effects of entropy. Fixing that may never be possible.
By comparison, putting your head on a young body looks comparatively easy—a way to bypass aging in a single stroke, at least as long as your brain holds out. The idea was strongly endorsed in a technical road map put forward this year by the Longevity Biotech Fellowship, a group espousing radical life extension, which rated “body replacement” as the cheapest, fastest pathway to “solve aging.”
Will head transplants work? In a crude way, they already have. In the early 1970s, the American neurosurgeon Robert White performed a “cephalic exchange,” cutting off the head of a monkey, placing it on the body of another, and sewing together their circulatory systems. Reports suggest the head remained conscious, and able to see, for a few days before it died.
Most likely, a human head transplant would also be fatal. But even if you lived, you’d be a mind atop a paralyzed body, since exchanging heads means severing the spinal cord.
Yet head-swapping proponents can point to plausible solutions for that, too—a number of which appear in the BrainBridge video. In Europe, for instance, some paralyzed people have walked again after doctors bridged their spinal injuries with electronics. Other scientists in China are studying growth factors to regrow nerves.
Joined at the neck
As shocking as the video is, BrainBridge is in some ways overly conventional in its thinking. If you want to keep your brain going, why must it be on a human body? You might instead keep the head alive on a heart-lung machine—with an Elon Musk neural implant to let it surf the internet, for as long as it lives. Or consider how doctors hoping to solve the organ shortage have started putting hearts and kidneys from genetically engineered pigs into patients. If you don’t mind having a tail and four legs, maybe your head could be placed onto a pig’s body.
Let’s take it a step further. Why does the body “donor” have to be dead at all? Anatomically, it’s possible to have two heads. There are conjoined twins who share one body. If your spouse were diagnosed with a fatal cancer, you would surely welcome his or her head next to yours, if it allowed their mind to live on. After all, the concept of a “living donor” is widely accepted in transplant medicine already, and married couples are often said to be joined at the hip. Why not at the neck, too?
If the video is an attempt to take the public’s temperature and gauge reactions, it’s been successful. Since it was posted, thousands of commenters have explored the moral dilemmas posed by the procedure. For instance, if someone is left brain dead—say, in a motorcycle accident—surgeons can use their heart, liver, and kidneys to save multiple other people. Would it be ethical to use a body to help only one person?
“The most common question is ‘Where do you get the bodies from?’” says Al-Ghaili. The BrainBridge website answers this question by stating it will source “ethically grown” unconscious bodies from EctoLife, the artificial womb company that is Al-Ghaili’s previous fiction. He also suggests that people undergoing euthanasia because of chronic pain, or even psychiatric problems, could provide an additional supply.
For the most part, the public seems to hate the idea. On Facebook, a pastor, Matthew. W. Tucker, called the concept “disgusting, immoral, unnecessary, pagan, demonic and outright idiotic,” adding that “they have no idea what they are doing.” A poster from the Middle East apologized for the video, joking that its creator “is one of our psychiatric patients who escaped last night.” “We urge the public to go about [their] business as everything is under control,” this person said.
Al-Ghaili is monitoring the feedback with interest and some concern. “The negativity is huge, to be honest,” he says. “But behind that are the ones who are sending emails. These are people who want to invest, or who are expressing their personal health challenges. These are the ones who matter.”
He says if suitable job applicants appear, the backers of BrainBridge are prepared to fund a small technical feasibility study to see if their idea has legs.
Modern life is noisy. If you don’t like it, noise-canceling headphones can reduce the sounds in your environment. But they muffle sounds indiscriminately, so you can easily end up missing something you actually want to hear.
A new prototype AI system for such headphones aims to solve this. Called Target Speech Hearing, the system gives users the ability to select a person whose voice will remain audible even when all other sounds are canceled out.
Although the technology is currently a proof of concept, its creators say they are in talks to embed it in popular brands of noise-canceling earbuds and are also working to make it available for hearing aids.
“Listening to specific people is such a fundamental aspect of how we communicate and how we interact in the world with other humans,” says Shyam Gollakota, a professor at the University of Washington, who worked on the project. “But it can get really challenging, even if you don’t have any hearing loss issues, to focus on specific people when it comes to noisy situations.”
The same researchers previously managed to train a neural network to recognize and filter out certain sounds, such as babies crying, birds tweeting, or alarms ringing. But separating out human voices is a tougher challenge, requiring much more complex neural networks.
That complexity is a problem when AI models need to work in real time in a pair of headphones with limited computing power and battery life. To meet such constraints, the neural networks needed to be small and energy efficient. So the team used an AI compression technique called knowledge distillation. This meant taking a huge AI model that had been trained on millions of voices (the “teacher”) and having it train a much smaller model (the “student”) to imitate its behavior and performance to the same standard.
The student was then taught to extract the vocal patterns of specific voices from the surrounding noise captured by microphones attached to a pair of commercially available noise-canceling headphones.
To activate the Target Speech Hearing system, the wearer holds down a button on the headphones for several seconds while facing the person to be focused on. During this “enrollment” process, the system captures an audio sample from both headphones and uses this recording to extract the speaker’s vocal characteristics, even when there are other speakers and noises in the vicinity.
These characteristics are fed into a second neural network running on a microcontroller computer connected to the headphones via USB cable. This network runs continuously, keeping the chosen voice separate from those of other people and playing it back to the listener. Once the system has locked onto a speaker, it keeps prioritizing that person’s voice, even if the wearer turns away. The more training data the system gains by focusing on a speaker’s voice, the better its ability to isolate it becomes.
For now, the system is only able to successfully enroll a targeted speaker whose voice is the only loud one present, butthe team aims to make it work even when the loudest voice in a particular direction is not the target speaker.
Singling out a single voice in a loud environment is very tough, says Sefik Emre Eskimez, a senior researcher at Microsoft who works on speech and AI, but who did not work on the research. “I know that companies want to do this,” he says. “If they can achieve it, it opens up lots of applications, particularly in a meeting scenario.”
While speech separation research tends to be more theoretical than practical, this work has clear real-world applications, says Samuele Cornell, a researcher at Carnegie Mellon University’s Language Technologies Institute, who did not work on the research. “I think it’s a step in the right direction,” Cornell says. “It’s a breath of fresh air.”
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
Meta says AI-generated election content is not happening at a “systemic level”
Meta has seen strikingly little AI-generated misinformation around the 2024 elections despite major votes in countries such as Indonesia, Taiwan, and Bangladesh, said the company’s president of global affairs, Nick Clegg, on Wednesday.
As voters will head to polls this year in more than 50 countries, experts have raised the alarm over AI-generated political disinformation and the prospect that malicious actors will use generative AI and social media to interfere with elections. And even well-resourced tech giants like Meta are struggling to keep up. Read the full story.
—Melissa Heikkilä
To read more about elections and AI, check out:
+ How generative AI is boosting the spread of disinformation and propaganda. Governments are now using the tech to amplify censorship. Read the full story.
+ Eric Schmidt has a 6-point plan for fighting election misinformation. Read the full story.
AI is an energy hog. This is what it means for climate change.
Tech companies keep finding new ways to bring AI into every facet of our lives. But the technology comes with rising electricity demand. You may have seen the headlines proclaiming that AI uses as much electricity as small countries, that it’ll usher in a fossil-fuel resurgence, and that it’s already challenging the grid.
So how worried should we be about AI’s electricity demands? Casey Crownhart, our climate reporter, has dug into the data. Read the full story.
This story is from The Spark, our weekly climate and energy newsletter. Sign up to receive it in your inbox every Wednesday.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 A second human has been diagnosed with bird flu Thankfully, the Michigan farmworker has since recovered. (NY Mag $) + Shares in vaccine makers are rising as a result. (FT $) + Here’s what you need to know about the current outbreak. (MIT Technology Review)
2 Nvidia has reported stratospheric growth The chipmaker’s revenue grew a whopping 262% over the past quarter. (FT $) + That’s $14 billion worth of profit. (The Verge) + What’s next in chips. (MIT Technology Review)
3 News Corp has struck a deal with OpenAI News from the media giant’s newspapers will appear in ChatGPT responses. (WP $) + The deal is valued at more than $250 million. (WSJ $) + Meta is reported to be interested in making deals with news outlets, too. (Insider $)
4 The US is planning on suing Ticketmaster A collection of states and the Justice Department will accuse it of running a monopoly. (NYT $)
5 We know that Russia wants to put a nuke in space But beyond that, details are pretty unclear. (Vox) + How to fight a war in space (and get away with it) (MIT Technology Review)
6 The US House of Representative has passed a crypto bill Despite the Securities regulator’s misgivings. (Reuters)
7 Amazon wants a new challenge: tackling your returns It’s running a pilot at several warehouses to test if it can manage returns as well as deliveries. (The Information $)
8 Weight loss drugs are really expensive Their high price tag is forcing doctors to get creative. (The Atlantic $) + Weight-loss injections have taken over the internet. But what does this mean for people IRL? (MIT Technology Review)
9 What we lose when we use apps to speed read books Squishing down books into brief summaries doesn’t exactly make for a joyful reading experience. (New Yorker $)
10 How to make your phone work for you No more doomscrolling! (WSJ $) + How to log off. (MIT Technology Review)
Quote of the day
“The AI revolution starts with Nvidia, and in our view, the AI party is just getting started.”
—Analyst Dan Ives, from Wedbush Securities, explains why investors will be following chipmaker Nvidia even more closely after the company announced blockbuster financial results, the Guardian reports.
The big story
The quest to learn if our brain’s mutations affect mental health
August 2021
Scientists have struggled in their search for specific genes behind most brain disorders, including autism and Alzheimer’s disease. Unlike problems with some other parts of our body, the vast majority of brain disorder presentations are not linked to an identifiable gene.
But a University of California, San Diego study published in 2001 suggested a different path. What if it wasn’t a single faulty gene—or even a series of genes—that always caused cognitive issues? What if it could be the genetic differences between cells?
The explanation had seemed far-fetched, but more researchers have begun to take it seriously. Scientists already knew that the 85 billion to 100 billion neurons in your brain work to some extent in concert—but what they want to know is whether there is a risk when some of those cells might be singing a different genetic tune. Read the full story.
—Roxanne Khamsi
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or tweet ’em at me.)
+ Who knew that Sting had been secretly working on a ferry all this time? + That’s some seriously impressive skipping. + America is home to some of the most beautiful train rides on Earth. + This Middle Earth tattoo is bonkers.
This article is from The Spark, MIT Technology Review’s weekly climate newsletter. To receive it in your inbox every Wednesday, sign up here.
Tech companies keep finding new ways to bring AI into every facet of our lives. AI has taken over my search engine results, and new virtual assistants from Google and OpenAI announced last week are bringing the world eerily close to the 2013 film Her (in more ways than one).
So how worried should we be about AI’s electricity demands? Well, it’s complicated.
Using AI for certain tasks can come with a significant energy price tag. With some powerful AI models, generating an image can require as much energy as charging up your phone, as my colleague Melissa Heikkilä explained in a story from December. Create 1,000 images with a model like Stable Diffusion XL, and you’ve produced as much carbon dioxide as driving just over four miles in a gas-powered car, according to the researchers Melissa spoke to.
But while generated images are splashy, there are plenty of AI tasks that don’t use as much energy. For example, creating images is thousands of times more energy-intensive than generating text. And using a smaller model that’s tailored to a specific task, rather than a massive, all-purpose generative model, can be dozens of times more efficient. In any case, generative AI models require energy, and we’re using them a lot.
Electricity consumption from data centers, AI, and cryptocurrency could reach double 2022 levels by 2026, according to projections from the International Energy Agency. Those technologies together made up roughly 2% of global electricity demand in 2022. Note that these numbers aren’t just for AI—it’s tricky to nail down AI’s specific contribution, so keep that in mind when you see predictions about electricity demand from data centers.
There’s a wide range of uncertainty in the IEA’s projections, depending on factors like how quickly deployment increases and how efficient computing processes get. On the low end, the sector could require about 160 terawatt-hours of additional electricity by 2026. On the higher end, that number might be 590 TWh. As the report puts it, AI, data centers, and cryptocurrency together are likely adding “at least one Sweden or at most one Germany” to global electricity demand.
In total, the IEA projects, the world will add about 3,500 TWh of electricity demand over that same period—so while computing is certainly part of the demand crunch, it’s far from the whole story. Electric vehicles and the industrial sector will both be bigger sources of growth in electricity demand than data centers in the European Union, for example.
Still, some big tech companies are suggesting that AI could get in the way of their climate goals. Microsoft pledged four years ago to bring its greenhouse-gas emissions to zero (or even lower) by the end of the decade. But the company’s recent sustainability report shows that instead, emissions are still ticking up, and some executives point to AI as a reason. “In 2020, we unveiled what we called our carbon moonshot. That was before the explosion in artificial intelligence,” Brad Smith, Microsoft’s president, told Bloomberg Green.
What I found interesting, though, is that it’s not AI’s electricity demand that’s contributing to Microsoft’s rising emissions, at least on paper. The company has agreements in place and buys renewable-energy credits so that electricity needs for all its functions (including AI) are met with renewables. (How much these credits actually help is questionable, but that’s a story for another day.)
Instead, infrastructure growth could be adding to the uptick in emissions. Microsoft plans to spend $50 billion between July 2023 and June 2024 on expanding data centers to meet demand for AI products, according to the Bloomberg story. Building those data centers requires materials that can be carbon intensive, like steel, cement, and of course chips.
Meyer points to estimates from 1999 that information technologies were already accounting for up to 13% of US power demand, and that personal computers and the internet could eat up half the grid’s capacity within the decade. That didn’t end up happening, and even at the time, computing was actually accounting for something like 3% of electricity demand.
We’ll have to wait and see if doomsday predictions about AI’s energy demand play out. The way I see it, though, AI is probably going to be a small piece of a much bigger story. Ultimately, rising electricity demand from AI is in some ways no different from rising demand from EVs, heat pumps, or factory growth. It’s really how we meet that demand that matters.
If we build more fossil-fuel plants to meet our growing electricity demand, it’ll come with negative consequences for the climate. But if we use rising electricity demand as a catalyst to lean harder into renewable energy and other low-carbon power sources, and push AI to get more efficient, doing more with less energy, then we can continue to slowly clean up the grid, even as AI continues to expand its reach in our lives.
Now read the rest of The Spark
Related reading
Check out my colleague Melissa’s story on the carbon footprint of AI from December here.
For a closer look at Microsoft’s new sustainability report and the effects of AI, give this Bloomberg Greenstory from reporters Akshat Rathi and Dina Bass a read.
Robinson Meyer at Heatmap dug into the context around the AI energy demand in this April piece.
Another thing
Missed our event last week on thermal batteries? Good news—the recording is now available for subscribers!
For the latest in our Roundtables series, I spoke with Amy Nordrum, MIT Technology Review executive editor, about how the technology works, who the crucial players are, and what I’m watching for next. Check it out here.
Keeping up with climate
Changing how we generate heat in industry will be crucial to cleaning up that sector in China, according to a new report. Thermal batteries and heat pumps could meet most of the demand. (Axios)
Form Energy is known for its iron-air batteries, which could help unlock cheap energy storage on the grid. Now, the company is working on research to produce green iron. (Canary Media)
The NET Power pilot in Texas is working to generate electricity with natural gas while capturing the vast majority of emissions. But carbon capture technology in power plants is far from proven. (Cipher News)
MIT spinoff Electrified Thermal Solutions is working to bring its thermal battery technology to commercial use. The company’s product is roughly the size of an elevator and can reach temperatures up to 1,800 °C. (Inside Climate News)
Mexico City has seen constant struggles over water. Now groundwater is drying up, and a system of dams and canals may soon be unable to provide water to the city. (New York Times)
Sodium-ion batteries could offer cheap energy storage while avoiding material crunches for metals like lithium, nickel, and cobalt. China has a massive head start, leaving other countries scrambling to catch up. (Latitude Media)
→ Here’s how this abundant material could unlock cheaper energy storage. (MIT Technology Review)
Biochar is made by heating up biomass like wood and plants in low-oxygen environments. It’s a simple approach to carbon removal, but it doesn’t always get as much attention as other carbon removal technologies. (Heatmap)
This startup wants ships to capture their own emissions by bubbling exhaust through seawater and limestone and dumping it into the ocean. Experts caution that some components of the exhaust could harm sea life if they’re not handled properly. (New Scientist)
Meta has seen strikingly little AI-generated misinformation around the 2024 elections despite major votes in countries such as Indonesia, Taiwan, and Bangladesh, said the company’s president of global affairs, Nick Clegg, on Wednesday.
“It is there; it is discernible. It’s really not happening on … a volume or a systemic level,” he said. Clegg said Meta has seen attempts at interference in, for example, the Taiwanese election, but that the scale of that interference is at a “manageable amount.”
As voters will head to polls this year in more than 50 countries, experts have raised the alarm over AI-generated political disinformation and the prospect that malicious actors will use generative AI and social media to interfere with elections. Meta has previously faced criticism over its content moderation policies around past elections—for example, when it failed to prevent the January 6 rioters from organizing on its platforms.
Clegg defended the company’s efforts at preventing violent groups from organizing, but he also stressed the difficulty of keeping up. “This is a highly adversarial space. You play Whack-a-Mole, candidly. You remove one group, they rename themselves, rebrand themselves, and so on,” he said.
Clegg argued that compared with 2016, the company is now “utterly different” when it comes to moderating election content. Since then, it has removed over 200 “networks of coordinated inauthentic behavior,” he said. The company now relies on fact checkers and AI technology to identify unwanted groups on its platforms.
Earlier this year, Meta announced it would label AI-generated images on Facebook, Instagram, and Threads. Meta has started adding visible markers to such images, as well as invisible watermarks and metadata in the image file. The watermarks will be added to images created using Meta’s generative AI systems or ones that carry invisible industry-standard markers. The company says its measures are in line with best practices laid out by the Partnership on AI, an AI research nonprofit.
But at the same time, Clegg admitted that tools to detect AI-generated content are still imperfect and immature. Watermarks in AI systems are not adopted industry-wide, and they are easy to tamper with. They are also hard to implement robustly in AI-generated text, audio, and video.
Ultimately that should not matter, Clegg said, because Meta’s systems should be able to catch and detect mis- and disinformation regardless of its origins.
“AI is a sword and a shield in this,” he said.
Clegg also defended the company’s decision to allow ads claiming that the 2020 US election was stolen, noting that these kinds of claims are common throughout the world and saying it’s “not feasible” for Meta to relitigate past elections. Just this month, eight state secretaries of state wrote a letter to Meta CEO Mark Zuckerberg arguing that the ads could still be dangerous, and that they have the potential to further threaten public trust in elections and the safety of individual election workers.
You can watch the full interview with Nick Clegg and MIT Technology Review executive editor Amy Nordrum below.
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
Five ways criminals are using AI
Artificial intelligence has brought a big boost in productivity—to the criminal underworld.
Generative AI provides a new, powerful tool kit that allows malicious actors to work far more efficiently and internationally than ever before. Over the past year, cybercriminals have mostly stopped developing their own AI models. Instead, they are opting for tricks with existing tools that work reliably.
OpenAI’s latest blunder shows the challenges facing Chinese AI models
Last week’s release of GPT-4o, a new AI “omnimodel”, was supposed to be a big moment for OpenAI. But just days later, it feels as if the company is in big trouble. From the resignation of most of its safety team to Scarlett Johansson’s accusation that it replicated her voice for the model against her consent, it’s now in damage-control mode.
On top of that, the data it used to train GPT-4o’s tokenizer—a tool that helps the model parse and process text more efficiently—is polluted by Chinese spam websites. As a result, the model’s Chinese token library is full of phrases related to pornography and gambling. This could worsen some problems that are common with AI models: hallucinations, poor performance, and misuse.
But OpenAI is not the only company struggling with this problem: there are some steep challenges associated with training large language models to speak Chinese. Read our story to learn more.
—Zeyi Yang
This story is from China Report, our weekly newsletter giving you the inside track on tech in China. Sign up to receive it in your inbox every Tuesday.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 AI just got a little less mysterious Anthropic has delved into how artificial neural networks work. (NYT $) + Understanding more about how AI makes decisions could help us control it. (Wired $) + Large language models can do jaw-dropping things. But nobody knows exactly why. (MIT Technology Review)
2 Google is testing ads in its AI-generated search results Sponsored query answers? No thanks. (Reuters) + Why you shouldn’t trust AI search engines. (MIT Technology Review)
3 China has created a chatbot trained on the thoughts of Xi Jinping But we’ll have to wait to see how popular that’ll be, as it’s still a way off from being released to the wider public. (FT $) + Why the Chinese government is sparing AI from harsh regulations—for now. (MIT Technology Review)
4 Our drinking water is major hacking target Default passwords are to blame. (IEEE Spectrum)
5 Humane is looking for a buyer Just weeks after its AI pin device got slated in reviews. (Bloomberg $)
6 How a massive corporation covered up the dangers of forever chemicals And kept selling them afterwards. (New Yorker $) + The race to destroy PFAS, the forever chemicals. (MIT Technology Review)
7 Inside the fight for America’s broadband Campaign groups are clashing with service providers over access. (Ars Technica)
8 Sailboats are making a comeback And the sails have had a high-tech makeover. (Economist $)
9 Can beef ever really be climate-friendly? The US branded a meat packer environmentally friendly. Pressure groups aren’t so sure. (Undark Magazine) + How I learned to stop worrying and love fake meat. (MIT Technology Review)
10 Admire the beauty of Earth from the ISS These new photographs are truly breathtaking. (The Atlantic $)
Quote of the day
“I wish we had called it ‘different intelligence’. Because I have my intelligence. I don’t need any artificial intelligence.”
—Satya Nadella, Microsoft’s chief executive, is worried about people giving AI systems too much credit, he tells Bloomberg.
The big story
Bringing the lofty ideas of pure math down to earth
April 2023
—Pradeep Niroula
Mathematics has long been presented as a sanctuary from confusion and doubt, a place to go in search of answers. Perhaps part of the mystique comes from the fact that biographies of mathematicians often paint them as otherworldly savants.
As a graduate student in physics, I have seen the work that goes into conducting delicate experiments, but the daily grind of mathematical discovery is a ritual altogether foreign to me. And this feeling is only reinforced by popular books on math, which often take the tone of a pastor dispensing sermons to the faithful.
Luckily, there are ways to bring it back down to earth. Popular math books seek a fresher take on these old ideas, be it through baking recipes or hot-button political issues. My verdict: Why not? It’s worth a shot. Read the full story.
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or tweet ’em at me.)
+ Spare a thought for the Kyles of the world, 706 of whom traveled to the city of Kyle, Texas, only to be told they hadn’t broken a world record. + Why are spirographs so hypnotic? + If you’re into Impressionism, there’s a whole host of impressive-looking shows taking place this year. + Here’s what went down when the Beach Boys met the Beatles.
This story first appeared in China Report, MIT Technology Review’s newsletter about technology in China. Sign up to receive it in your inbox every Tuesday.
Last week’s release of GPT-4o, a new AI “omnimodel” that you can interact with using voice, text, or video, was supposed to be a big moment for OpenAI. But just days later, it feels as if the company is in big trouble. From the resignation of most of its safety team to Scarlett Johansson’s accusation that it replicated her voice for the model against her consent, it’s now in damage-control mode.
Add to that another thing OpenAI fumbled with GPT-4o: the data it used to train its tokenizer—a tool that helps the model parse and process text more efficiently—is polluted by Chinese spam websites. As a result, the model’s Chinese token library is full of phrases related to pornography and gambling. This could worsen some problems that are common with AI models: hallucinations, poor performance, and misuse.
I wrote about it on Friday after several researchers and AI industry insiders flagged the problem. They took a look at GPT-4o’s public token library, which has been significantly updated with the new model to improve support of non-English languages, and saw that more than 90 of the 100 longest Chinese tokens in the model are from spam websites. These are phrases like “_free Japanese porn video to watch,” “Beijing race car betting,” and “China welfare lottery every day.”
Anyone who reads Chinese could spot the problem with this list of tokens right away. Some such phrases inevitably slip into training data sets because of how popular adult content is online, but for them to account for 90% of the Chinese language used to train the model? That’s alarming.
“It’s an embarrassing thing to see as a Chinese person. Is that just how the quality of the [Chinese] data is? Is it because of insufficient data cleaning or is the language just like that?” says Zhengyang Geng, a PhD student in computer science at Carnegie Mellon University.
It could be tempting to draw a conclusion about a language or a culture from the tokens OpenAI chose for GPT-4o. After all, these are selected as commonly seen and significant phrases from the respective languages. There’s an interesting blog post by a Hong Kong–based researcher named Henry Luo, who queried the longest GPT-4o tokens in various different languages and found that they seem to have different themes. While the tokens in Russian reflect language about the government and public institutions, the tokens in Japanese have a lot of different ways to say “thank you.”
But rather than reflecting the differences between cultures or countries, I think this explains more about what kind of training data is readily available online, and the websites OpenAI crawled to feed into GPT-4o.
After I published the story, Victor Shih, a political science professor at the University of California, San Diego, commented on it on X: “When you try not [to] train on Chinese state media content, this is what you get.”
It’s half a joke, and half a serious point about the two biggest problems in training large language models to speak Chinese: the readily available data online reflects either the “official,” sanctioned way of talking about China or the omnipresent spam content that drowns out real conversations.
In fact, among the few long Chinese tokens in GPT-4o that aren’t either pornography or gambling nonsense, two are “socialism with Chinese characteristics” and “People’s Republic of China.” The presence of these phrases suggests that a significant part of the training data actually is from Chinese state media writings, where formal, long expressions are extremely common.
OpenAI has historically been very tight-lipped about the data it uses to train its models, and it probably will never tell us how much of its Chinese training database is state media and how much is spam. (OpenAI didn’t respond to MIT Technology Review’s detailed questions sent on Friday.)
But it is not the only company struggling with this problem. People inside China who work in its AI industry agree there’s a lack of quality Chinese text data sets for training LLMs. One reason is that the Chinese internet used to be, and largely remains, divided up by big companies like Tencent and ByteDance. They own most of the social platforms and aren’t going to share their data with competitors or third parties to train LLMs.
In fact, this is also why search engines, including Google, kinda suck when it comes to searching in Chinese. Since WeChat content can only be searched on WeChat, and content on Douyin (the Chinese TikTok) can only be searched on Douyin, this data is not accessible to a third-party search engine, let alone an LLM. But these are the platforms where actual human conversations are happening, instead of some spam website that keeps trying to draw you into online gambling.
The lack of quality training data is a much bigger problem than the failure to filter out the porn and general nonsense in GPT-4o’s token-training data. If there isn’t an existing data set, AI companies have to put in significant work to identify, source, and curate their own data sets and filter out inappropriate or biased content.
It doesn’t seem OpenAI did that, which in fairness makes some sense, given that people in China can’t use its AI models anyway.
Still, there are many people living outside China who want to use AI services in Chinese. And they deserve a product that works properly as much as speakers of any other language do.
How can we solve the problem of the lack of good Chinese LLM training data? Tell me your idea at zeyi@technologyreview.com.
Now read the rest of China Report
Catch up with China
1. China launched an anti-dumping investigation into imports of polyoxymethylene copolymer—a widely used plastic in electronics and cars—from the US, the EU, Taiwan, and Japan. It’s widely seen as a response to the new US tariff announced on Chinese EVs. (BBC)
Meanwhile, Latin American countries, including Mexico, Chile, and Brazil, have increased tariffs on Chinese-imported steel, testing China’s relationship with the region. (Bloomberg $)
2. China’s solar-industry boom is incentivizing farmers to install solar panels and make some extra cash by selling the electricity they generate. (Associated Press)
3. Hedging against the potential devaluation of the RMB, Chinese buyers are pushing the price of gold to all-time highs. (Financial Times $)
4. The Shanghai government set up a pilot project that allows data to be transferred out of China without going through the much-dreaded security assessments, a move that has been sought by companies like Tesla. (Reuters $)
5. China’s central bank fined seven businesses—including a KFC and branches of state-owned corporations—for rejecting cash payments. The popularization of mobile payment has been a good thing, but the dwindling support for cash is also making life harder for people like the elderly and foreign tourists. (Business Insider $)
6. Alibaba and Baidu are waging an LLM price war in China to attract more users. (Bloomberg $)
7. The Chinese government has sanctioned Mike Gallagher, a former Republican congressman who chaired the Select Committee on China and remains a fierce critic of Beijing. (NBC News)
Lost in translation
China’s National Health Commission is exploring the relaxation of stringent rules around human genetic data to boost the biotech industry, according to the Chinese publication Caixin. A regulation enacted in 1998 required any research that involves the use of this data to clear an approval process. And there’s even more scrutiny if the research involves foreign institutions.
In the early years of human genetic research, the regulation helped prevent the nonconsensual collection of DNA. But as the use of genetic data becomes increasingly important in discovering new treatments, the industry has been complaining about the bureaucracy, which can add an extra two to four months to research projects. Now the government is holding discussions on how to revise the regulation, potentially lifting the approval process for smaller-scale research and more foreign entities, as part of a bid to accelerate the growth of biotech research in China.
One more thing
Did you know that the Beijing Capital International Airport has been employing birds of prey to chase away other birds since 2019? This month, the second generation of Beijing’s birdy employees started their work driving away the migratory birds that could endanger aircraft. The airport even has different kinds of raptors—Eurasian hobbies, Eurasian goshawks, and Eurasian sparrowhawks—to deal with the different bird species that migrate to Beijing at different times.
Artificial intelligence has brought a big boost in productivity—to the criminal underworld.
Generative AI provides a new, powerful tool kit that allows malicious actors to work far more efficiently and internationally than ever before, says Vincenzo Ciancaglini, a senior threat researcher at the security company Trend Micro.
Most criminals are “not living in some dark lair and plotting things,” says Ciancaglini. “Most of them are regular folks that carry on regular activities that require productivity as well.”
Last year saw the rise and fall of WormGPT, an AI language model built on top of an open-source model and trained on malware-related data, which was created to assist hackers and had no ethical rules or restrictions. But last summer, its creators announced they were shutting the model down after it started attracting media attention. Since then, cybercriminals have mostly stopped developing their own AI models. Instead, they are opting for tricks with existing tools that work reliably.
That’s because criminals want an easy life and quick gains, Ciancaglini explains. For any new technology to be worth the unknown risks associated with adopting it—for example, a higher risk of getting caught—it has to be better and bring higher rewards than what they’re currently using.
Here are five ways criminals are using AI now.
Phishing
The biggest use case for generative AI among criminals right now is phishing, which involves trying to trick people into revealing sensitive information that can be used for malicious purposes, says Mislav Balunović, an AI security researcher at ETH Zurich. Researchers have found that the rise of ChatGPT has been accompanied by a huge spike in the number of phishing emails.
Spam-generating services, such as GoMail Pro, have ChatGPT integrated into them, which allows criminal users to translate or improve the messages sent to victims, says Ciancaglini. OpenAI’s policies restrict people from using their products for illegal activities, but that is difficult to police in practice, because many innocent-sounding prompts could be used for malicious purposes too, says Ciancaglini.
OpenAI says it uses a mix of human reviewers and automated systems to identify and enforce against misuse of its models, and issues warnings, temporary suspensions and bans if users violate the company’s policies.
“We take the safety of our products seriously and are continually improving our safety measures based on how people use our products,” a spokesperson for OpenAI told us. “We are constantly working to make our models safer and more robust against abuse and jailbreaks, while also maintaining the models’ usefulness and task performance,” they added.
In a report from February, OpenAI said it had closed five accounts associated with state-affiliated malicous actors.
Before, so-called Nigerian prince scams, in which someone promises the victim a large sum of money in exchange for a small up-front payment, were relatively easy to spot because the English in the messages was clumsy and riddled with grammatical errors, Ciancaglini. says. Language models allow scammers to generate messages that sound like something a native speaker would have written.
“English speakers used to be relatively safe from non-English-speaking [criminals] because you could spot their messages,” Ciancaglini says. That’s not the case anymore.
Thanks to better AI translation, different criminal groups around the world can also communicate better with each other. The risk is that they could coordinate large-scale operations that span beyond their nations and target victims in other countries, says Ciancaglini.
Deepfake audio scams
Generative AI has allowed deepfake development to take a big leap forward, with synthetic images, videos, and audio looking and sounding more realistic than ever. This has not gone unnoticed by the criminal underworld.
Earlier this year, an employee in Hong Kong was reportedly scammed out of $25 million after cybercriminals used a deepfake of the company’s chief financial officer to convince the employee to transfer the money to the scammer’s account. “We’ve seen deepfakes finally being marketed in the underground,” says Ciancaglini. His team found people on platforms such as Telegram showing off their “portfolio” of deepfakes and selling their services for as little as $10 per image or $500 per minute of video. One of the most popular people for criminals to deepfake is Elon Musk, says Ciancaglini.
And while deepfake videos remain complicated to make and easier for humans to spot, that is not the case for audio deepfakes. They are cheap to make and require only a couple of seconds of someone’s voice—taken, for example, from social media—to generate something scarily convincing.
In the US, there have been high-profile cases where people have received distressing calls from loved ones saying they’ve been kidnapped and asking for money to be freed, only for the caller to turn out to be a scammer using a deepfake voice recording.
“People need to be aware that now these things are possible, and people need to be aware that now the Nigerian king doesn’t speak in broken English anymore,” says Ciancaglini. “People can call you with another voice, and they can put you in a very stressful situation,” he adds.
There are some for people to protect themselves, he says. Ciancaglini recommends agreeing on a regularly changing secret safe word between loved ones that could help confirm the identity of the person on the other end of the line.
“I password-protected my grandma,” he says.
Bypassing identity checks
Another way criminals are using deepfakes is to bypass “know your customer” verification systems. Banks and cryptocurrency exchanges use these systems to verify that their customers are real people. They require new users to take a photo of themselves holding a physical identification document in front of a camera. But criminals have started selling apps on platforms such as Telegram that allow people to get around the requirement.
They work by offering a fake or stolen ID and imposing a deepfake image on top of a real person’s face to trick the verification system on an Android phone’s camera. Ciancaglini has found examples where people are offering these services for cryptocurrency website Binance for as little as $70.
“They are still fairly basic,” Ciancaglini says. The techniques they use are similar to Instagram filters, where someone else’s face is swapped for your own.
“What we can expect in the future is that [criminals] will use actual deepfakes … so that you can do more complex authentication,” he says.
An example of a stolen ID and a criminal using face swapping technology to bypass identity verification systems.
Jailbreak-as-a-service
If you ask most AI systems how to make a bomb, you won’t get a useful response.
That’s because AI companies have put in place various safeguards to prevent their models from spewing harmful or dangerous information. Instead of building their own AI models without these safeguards, which is expensive, time-consuming, and difficult, cybercriminals have begun to embrace a new trend: jailbreak-as-a-service.
Most models come with rules around how they can be used. Jailbreaking allows users to manipulate the AI system to generate outputs that violate those policies—for example, to write code for ransomware or generate text that could be used in scam emails.
Services such as EscapeGPT and BlackhatGPT offer anonymized access to language-model APIs and jailbreaking prompts that update frequently. To fight back against this growing cottage industry, AI companies such as OpenAI and Google frequently have to plug security holes that could allow their models to be abused.
Jailbreaking services use different tricks to break through safety mechanisms, such as posing hypothetical questions or asking questions in foreign languages. There is a constant cat-and-mouse game between AI companies trying to prevent their models from misbehaving and malicious actors coming up with ever more creative jailbreaking prompts.
These services are hitting the sweet spot for criminals, says Ciancaglini.
“Keeping up with jailbreaks is a tedious activity. You come up with a new one, then you need to test it, then it’s going to work for a couple of weeks, and then Open AI updates their model,” he adds. “Jailbreaking is a super-interesting service for criminals.”
Doxxing and surveillance
AI language models are a perfect tool for not only phishing but for doxxing (revealing private, identifying information about someone online), says Balunović. This is because AI language models are trained on vast amounts of internet data, including personal data, and can deduce where, for example, someone might be located.
As an example of how this works, you could ask a chatbot to pretend to be a private investigator with experience in profiling. Then you could ask it to analyze text the victim has written, and infer personal information from small clues in that text—for example, their age based on when they went to high school, or where they live based on landmarks they mention on their commute. The more information there is about them on the internet, the more vulnerable they are to being identified.
Balunović was part of a team of researchers that found late last year that large language models, such as GPT-4, Llama 2, and Claude, are able to infer sensitive information such as people’s ethnicity, location, and occupation purely from mundane conversations with a chatbot. In theory, anyone with access to these models could use them this way.
Since their paper came out, new services that exploit this feature of language models have emerged.
While the existence of these services doesn’t indicate criminal activity, it points out the new capabilities malicious actors could get their hands on. And if regular people can build surveillance tools like this, state actors probably have far better systems, Balunović says.
“The only way for us to prevent these things is to work on defenses,” he says.
Companies should invest in data protection and security, he adds.
For individuals, increased awareness is key. People should think twice about what they share online and decide whether they are comfortable with having their personal details being used in language models, Balunović says.
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
AI models can outperform humans in tests to identify mental states
Humans are complicated beings. The ways we communicate are multilayered, and psychologists have devised many kinds of tests to measure our ability to infer meaning and understanding from interactions with each other.
AI models are getting better at these tests. New research published has found that some large language models perform as well as, and in some cases better than, humans when presented with tasks designed to test the ability to track people’s mental states, known as “theory of mind.”
This doesn’t mean AI systems are actually able to work out how we’re feeling. But it does demonstrate that these models are performing better and better in experiments designed to assess abilities that psychologists believe are unique to humans. Read the full story.
—Rhiannon Williams
And, if you’re interested in learning more about why the way we test AI is so flawed, read this piece by our senior AI editor Will Douglas Heaven.
A device that zaps the spinal cord gave paralyzed people better control of their hands
Fourteen years ago, a journalist named Melanie Reid attempted a jump on horseback and fell. The accident left her mostly paralyzed from the chest down. Eventually she regained control of her right hand, but her left remained, in her own words, “useless.”
Now, thanks to a new noninvasive device that delivers electrical stimulation to the spinal cord, she has regained some control of her left hand. She can use it to sweep her hair into a ponytail, scroll on a tablet, and even squeeze hard enough to release a seatbelt latch. These may seem like small wins, but they’re crucial.
Reid was part of a 60-person clinical trial, from which the vast majority of participants benefited. The trial was the last hurdle before the researchers behind the device could request regulatory approval, and they hope it might be approved in the US by the end of the year. Read the full story.
—Cassandra Willyard
Join us at EmTech Digital this week!
Between the world leaders gathering in Seoul for the second AI Safety Summit this week and Google and OpenAI’s launches of their supercharged new models, Astra and GPT-4o, the timing could not be better. AI feels hotter than ever.
This year’s EmTech Digital, MIT Technology Review’s flagship AI conference, will be all about how we can harness the power of generative AI while mitigating its risks,and how the technology will affect the workforce, competitiveness, and democracy. We will also get a sneak peek into the AI labs of Google, OpenAI, Adobe, AWS, and others.
It’ll be held at the MIT campus and streamed live online from tomorrow, May 22-23. Readers of The Download get 30% off tickets with the code DOWNLOADD24—here’s how to register. See you there!
For a sneak peek at some of the most exciting sessions on the agenda, check out the latest edition of The Algorithm, our weekly AI newsletter. Sign up to receive it in your inbox every Monday.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 Scarlett Johansson denied OpenAI permission to use her voice But it created the eerily similar ‘Sky’ voice for its chatbots anyway. (Rolling Stone $) + OpenAI took down the voice after Johansson’s lawyers got in touch. (NYT $) + The company is reportedly talking with her legal team. (The Verge) + GPT-4o was weirdly flirty during its launch demo. (MIT Technology Review)
2 A host of chipmaker startups want to overtake Nvidia But the GPU giant is number one for a reason. (Economist $) + Nvidia’s rivals are backing an initiative to break its industry stranglehold. (FT $) + Modern chips need major computing power. Maybe light could help? (Quanta Magazine) + What’s next in chips. (MIT Technology Review)
3 Can we really credit an AI chatbot for preventing suicide? Chatbots are notoriously unpredictable—and that’s problematic. (404 Media) + A chatbot helped more people access mental-health services. (MIT Technology Review)
4 The current strain of bird flu could, in theory, jump to pigs Which would be seriously bad news for humans. (The Atlantic $) + The viral outbreak has killed tens of millions of birds to date. (NY Mag $) + Here’s what you need to know about bird flu. (MIT Technology Review)
5 The gig economy is attracting older workers The problem is, their policies are rarely designed to accommodate older people. (Rest of World)
6 A brain implant has restored a paralyzed man’s bilingual abilities It suggests that the brain isn’t overly picky about which language it’s handling. (Ars Technica) + Beyond Neuralink: Meet the other companies developing brain-computer interfaces. (MIT Technology Review)
7 Deleted photos have cropped up in iPhone’s users camera rolls At what point is something truly eradicated, then? (Wired $) + Apple has issued a fix, but not an explanation. (The Verge)
8 Google is pivoting away from its ambitious moonshots So its employees are taking a risk and going it alone. (Bloomberg $) + We need a moonshot for computing. (MIT Technology Review)
9 Do you voicenote? If you don’t yet, it’s only a matter of time until your friends start forcing you. (WP $)
10 This electric spoon tricks your tongue into tasting salt Pass the—oh never mind. (Reuters)
Quote of the day
“Dr Wright presents himself as an extremely clever person. However, in my judgment, he is not nearly as clever as he thinks he is.”
—Justice James Mellor, a UK judge, rules that computer scientist Craig Wright lied “extensively and repeatedly” in his quest to prove he is bitcoin creator Satoshi Nakamoto, Wired reports.
The big story
How one mine could unlock billions in EV subsidies
January 2024
On a farm near Tamarack, Minnesota, Talon Metals has uncovered one of America’s densest nickel deposits. Now it wants to begin tunneling deep into the rock to extract hundreds of thousands of metric tons of mineral-rich ore a year.
If regulators approve the mine, it could mark the starting point in what this mining exploration company claims would become the country’s first complete domestic nickel supply chain, running from the bedrock beneath the Minnesota earth to the batteries in electric vehicles across the nation.
Their experience forms a fascinating microcosm of how the Inflation Reduction Act’s rich subsidies are starting to filter down through the US economy. Read the full story.
—James Temple
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or tweet ’em at me.)
+ Over in London, the Science Museum’s weird and wonderful collection of random household gadgets is entering its final weeks. + Devastating news: the TikTok of the man in a bus in a hammock isn’t real. + Put the laptop away! European cafes have had enough of them. + If you’re planning a cruise this summer, here’s some handy tips on minimizing your chances of getting seasick.
This story originally appeared in The Algorithm, our weekly newsletter on AI. To get stories like this in your inbox first, sign up here.
I’m excited to spend this week in Cambridge, Massachusetts. I’m visiting the mothership for MIT Technology Review’s annual flagship AI conference, EmTech Digital, on May 22-23.
Between the world leaders gathering in Seoul for the second AI Safety Summit this week and Google and OpenAI’s launches of their supercharged new models, Astra and GPT-4o, the timing could not be better. AI feels hotter than ever.
This year’s EmTech will be all about how we can harness the power of generative AI while mitigating its risks,and how the technology will affect the workforce, competitiveness, and democracy. We will also get a sneak peek into the AI labs of Google, OpenAI, Adobe, AWS, and others.
This year’s top speakers include Nick Clegg, the president of global affairs at Meta, who will talk about what the platform intends to do to curb misinformation. In 2024, over 40 national elections will happen around the world, making it one of the most consequential political years in history. At the same time, generative AI has enabled an entirely new age of misinformation. And it’s all coalescing, with major shake-ups at social media companies and information platforms. MIT Technology Review’s executive editor Amy Nordrum will press Clegg on stage about what this all means for democracy.
Here are some other sessions I am excited about.
A Peek Inside Google’s plans Jay Yagnik, a vice president and engineering fellow at Google, will share what the history of AI can teach us about where the technology is going next and discuss Google’s vision for how to harness generative AI.
From the Labs of OpenAI Srinivas Narayanan, the vice president of applied AI at OpenAI, will share what the company has been building recently and what is coming next. In another session, Connor Holmes, who led work on video-generation AI Sora, will talk about how video-generation models could work as world simulators, and what this means for future AI models.
The Often-Overlooked Privacy Problems in AI Language models are prone to leaking private data. In this session Patricia Thaine, cofounder and CEO of Private AI, will explore methods that keep secrets secret and help organizations maintain compliance with privacy regulations.
A Word Is Worth a Thousand Pictures Cynthia Lu, senior director and head of applied research at Adobe, will walk us through the AI technology that Adobe is building and the ethical and legal implications of generated imagery. I’ve written about Adobe’s efforts to build generative AI in a non-exploitative way and how they’re paying off, so I’ll be interested to hear more about that.
AI in the ER Advances in medical image analysis are now enabling doctors to interpret radiology reports and automate incident documentation. This session by Polina Golland, the associate director of the MIT Computer Science and AI Laboratory, will explore both the challenges of working with sensitive personal data and the benefits of AI-assisted health care for patients.
Future Compute On Tuesday, May 21, we are also hosting Future Compute, a day looking at how businesses and technical leaders navigate adopting AI. We have tech leaders from Salesforce, Stack Overflow, Amazon, and more, discussing how they are managing the AI transformation, and what pitfalls to avoid.
I’d love to see you there, so if you can make it, sign up and come along! Readers of The Algorithm get 30% off tickets with the code ALGORITHMD24.
Now read the rest of The Algorithm
Deeper Learning
To kick off this busy week in AI, heavyweights such as Turing Prize winners Geoffrey Hinton and Yoshua Bengio, and a slew of other prominent academics and writers, have just written an op-ed published in Science calling for more investment in AI safety research. The op-ed, timed to coincide with the Seoul AI Safety Summit, represents the group’s wish list for leaders meeting to discuss AI. Many of the researchers behind the text have been heavily involved in consulting with governments and international organizations on the best approach to building safer AI systems.
They argue that tech companies and public funders should invest at least a third of their AI R&D budgets into AI safety, and that governments should mandate stricter AI safety standards and assessments rather than relying on voluntary measures. The piece calls for them to establish fast-acting AI oversight bodies and provide them with funding comparable to the budgets of safety agencies in other sectors. It also says governments should require AI companies to prove that their systems cannot cause harm.
But it’s hard to see this op-ed shifting things much. Tech companies have little incentive to spend money on measures that might slow down innovation and, crucially, product launches. Over the past few years, we’ve seen teams working on responsible AI take the hit during mass layoffs. Governments have shown more willingness to regulate AI in the last year or so, with the EU passing its first piece of comprehensive AI legislation, but this op-ed calls for them to go much further and faster.
Despite that, focusing on the hypothetical existential risks posed by AI remains controversial among researchers, with some experts arguing that it distracts from the very real problems AI is causing today. As my colleague Will Douglas Heaven wrote last June when the AI safety debate was at a fever pitch: “The Overton window has shifted. What were once extreme views are now mainstream talking points, grabbing not only headlines but the attention of world leaders.”
Even Deeper Learning
GPT-4o’s Chinese token-training data is polluted by spam and porn websites
Last Monday OpenAI released GPT-4o, an AI model that you can communicate with in real time via live voice conversation, video streams from your phone, and text. But just days later, Chinese speakers started to notice that something seemed off about it: the tokens it uses to parse text were full of phrases related to spam and porn.
Oops, AI did it again: Humans read in words, but LLMs analyze tokens—distinct units in a sentence. When it comes to the Chinese language, the new tokenizer used by GPT-4o has introduced a disproportionate number of meaningless phrases. In one example, the longest token in GPT-4o’s public token library literally means “_free Japanese porn video to watch.” Experts say that’s likely due to insufficient data cleaning and filtering before the tokenizer was trained. (MIT Technology Review)
Bits and Bytes
What’s next in chips Thanks to the boom in artificial intelligence, the world of chips is on the cusp of a huge tidal shift. We outline four trends to look for in the year ahead that will define what the chips of the future will look like, who will make them, and which new technologies they’ll unlock. (MIT Technology Review)
OpenAI and Google are launching supercharged AI assistants. Here’s how you can try them out. OpenAI unveiled its GPT-4o assistant last Monday, and Google unveiled its own work building supercharged AI assistants just a day later. My colleague James O’Donnell walks you through what you should know about how to access these new tools, what you might use them for, and how much it will cost.
OpenAI has lost its cofounder and dissolved the team focused on long-term AI risks Last week OpenAI cofounder Ilya Sutskever and Jan Leike, the co-lead of the startup’s superalignment team, announced they were leaving the company. The superalignment team was set up less than a year ago to develop ways to control superintelligent AI systems. Leike said he was leaving because OpenAI’s “safety culture and processes have taken a backseat to shiny products.” In Silicon Valley, money always wins. (CNBC)
Meta’s plan to win the AI race: give its tech away for free Mark Zuckerberg’s bet is that making powerful AI technology free will drive down competitors’ prices, making Meta’s tech more widespread while others build products on top of it—ultimately giving him more control over the future of AI. (The Wall Street Journal)
Sony Music Group has warned companies against using its content to train AI The record label says it opts out of indiscriminate AI training and has started sending letters to AI companies prohibiting them from mining text or data, scraping the internet, or using Sony’s content without licensing agreements. (Sony)
What do you do when an AI company takes your voice? Two voice actors are suing Lovo, a startup, claiming it illegally took recordings of their voices to train their AI model. (The New York Times)
Humans are complicated beings. The ways we communicate are multilayered, and psychologists have devised many kinds of tests to measure our ability to infer meaning and understanding from interactions with each other.
AI models are getting better at these tests. New research published today in Nature Human Behavior found that some large language models (LLMs) perform as well as, and in some cases better than, humans when presented with tasks designed to test the ability to track people’s mental states, known as “theory of mind.”
This doesn’t mean AI systems are actually able to work out how we’re feeling. But it does demonstrate that these models are performing better and better in experiments designed to assess abilities that psychologists believe are unique to humans. To learn more about the processes behind LLMs’ successes and failures in these tasks, the researchers wanted to apply the same systematic approach they use to test theory of mind in humans.
In theory, the better AI models are at mimicking humans, the more useful and empathetic they can seem in their interactions with us. Both OpenAI and Google announced supercharged AI assistants last week; GPT-4o and Astra are designed to deliver much smoother, more naturalistic responses than their predecessors. But we must avoid falling into the trap of believing that their abilities are humanlike, even if they appear that way.
“We have a natural tendency to attribute mental states and mind and intentionality to entities that do not have a mind,” says Cristina Becchio, a professor of neuroscience at the University Medical Center Hamburg-Eppendorf, who worked on the research. “The risk of attributing a theory of mind to large language models is there.”
Theory of mind is a hallmark of emotional and social intelligence that allows us to infer people’s intentions and engage and empathize with one another. Most children pick up these kinds of skills between three and five years of age.
The researchers tested two families of large language models, OpenAI’s GPT-3.5 and GPT-4 and three versions of Meta’s Llama, on tasks designed to test the theory of mind in humans, including identifying false beliefs, recognizing faux pas, and understanding what is being implied rather than said directly. They also tested 1,907 human participants in order to compare the sets of scores.
The team conducted five types of tests. The first, the hinting task, is designed to measure someone’s ability to infer someone else’s real intentions through indirect comments. The second, the false-belief task, assesses whether someone can infer that someone else might reasonably be expected to believe something they happen to know isn’t the case. Another test measured the ability to recognize when someone is making a faux pas, while a fourth test consisted of telling strange stories, in which a protagonist does something unusual, in order to assess whether someone can explain the contrast between what was said and what was meant. They also included a test of whether people can comprehend irony.
The AI models were given each test 15 times in separate chats, so that they would treat each request independently, and their responses were scored in the same manner used for humans. The researchers then tested the human volunteers, and the two sets of scores were compared.
Both versions of GPT performed at, or sometimes above, human averages in tasks that involved indirect requests, misdirection, and false beliefs, while GPT-4 outperformed humans in the irony, hinting, and strange stories tests. Llama 2’s three models performed below the human average.
However, Llama 2, the biggest of the three Meta models tested, outperformed humans when it came to recognizing faux pas scenarios, whereas GPT consistently provided incorrect responses. The authors believe this is due to GPT’s general aversion to generating conclusions about opinions, because the models largely responded that there wasn’t enough information for them to answer one way or another.
“These models aren’t demonstrating the theory of mind of a human, for sure,” he says. “But what we do show is that there’s a competence here for arriving at mentalistic inferences and reasoning about characters’ or people’s minds.”
One reason the LLMs may have performed as well as they did was that these psychological tests are so well established, and were therefore likely to have been included in their training data, says Maarten Sap, an assistant professor at Carnegie Mellon University, who did not work on the research. “It’s really important to acknowledge that when you administer a false-belief test to a child, they have probably never seen that exact test before, but language models might,” he says.
Ultimately, we still don’t understand how LLMs work. Research like this can help deepen our understanding of what these kinds of models can and cannot do, says Tomer Ullman, a cognitive scientist at Harvard University, who did not work on the project. But it’s important to bear in mind what we’re really measuring when we set LLMs tests like these. If an AI outperforms a human on a test designed to measure theory of mind, it does not mean that AI has theory of mind. “I’m not anti-benchmark, but I am part of a group of people who are concerned that we’re currently reaching the end of usefulness in the way that we’ve been using benchmarks,” Ullman says. “However this thing learned to pass the benchmark, it’s not— I don’t think—in a human-like way.”
Fourteen years ago, a journalist named Melanie Reid attempted a jump on horseback and fell. The accident left her mostly paralyzed from the chest down. Eventually she regained control of her right hand, but her left remained “useless,” she told reporters at a press conference last week.
Now, thanks to a new noninvasive device that delivers electrical stimulation to the spinal cord, she has regained some control of her left hand. She can use it to sweep her hair into a ponytail, scroll on a tablet, and even squeeze hard enough to release a seatbelt latch. These may seem like small wins, but they’re crucial, Reid says.
“Everyone thinks that [after] spinal injury, all you want to do is be able to walk again. But if you’re a tetraplegic or a quadriplegic, what matters most is working hands,” she said.
Reid received the device, called ARCex, as part of a 60-person clinical trial. She and the other participants completed two months of physical therapy, followed by two months of physical therapy combined with stimulation. The results, published today in Nature Medicine, show that the vast majority of participants benefited. By the end of the four-month trial, 72% experienced some improvement in both strength and function of their hands or arms when the stimulator was turned off. Ninety percent had improvement in at least one of those measures. And 87% reported an improvement in their quality of life.
This isn’t the first study to test whether noninvasive stimulation of the spine can help people who are paralyzed regain function in their upper body, but it’s important because a trial has never been done before in this number of rehabilitation centers or in this number of subjects, says Igor Lavrov, a neuroscientist at the Mayo Clinic in Minnesota, who was not involved in the study. He points out, however, that the therapy seems to work best in people who have some ability to move below the site of their injury.
The trial was the last hurdle before the researchers behind the device could request regulatory approval, and they hope it might be approved in the US by the end of the year.
ARCex consists of a small stimulator connected by wires to electrodes placed on the spine—in this case, in the area responsible for hand and arm control, just below the neck. It was developed by Onward Medical, a company cofounded by Grégoire Courtine, a neuroscientist at the Swiss Federal Institute of Technology in Lausanne and now chief scientific officer at the company.
The stimulation won’t work in the small percentage of people who have no remaining connection between the brain and spine below their injury. But for people who still have a connection, the stimulation appears to make voluntary movements easier by making the nerves more likely to transmit a signal. Studies over the past couple of decades in animals suggest that the stimulation activates remaining nerve fibers and, over time, helps new nerves grow. That’s why the benefits persist even when the stimulator is turned off.
The big advantage of an external stimulation system over an implant is that it doesn’t require surgery, which makes using the device less of a commitment. “There are many, many people who are not interested in invasive technologies,” said Edelle Field-Fote, director of research on spinal cord injury at the Shepherd Center, at the press conference. An external device is also likely to be cheaper than any surgical options, although the company hasn’t yet set a price on ARCex.
“What we’re looking at here is a device that integrates really seamlessly with the physical therapy and occupational therapy that’s already offered in the clinic,” said Chet Moritz, an engineer and neuroscientist at the University of Washington in Seattle, at the press conference. The rehab that happens soon after the injury is crucial, because that’s when the opportunity for recovery is greatest. “Being able to bring that function back without requiring a surgery could be life-changing for the majority of people with spinal cord injury,” he adds.
Reid wishes she could have used the device soon after her injury, but she is astonished by the amount of function she was able to regain after all this time. “After 14 years, you think, well, I am where I am and nothing’s going change,” she says. So to suddenly find she had strength and power in her left hand—“It was extraordinary,” she says.
Onward is also developing implantable devices, which can deliver stronger, more targeted stimulation and thus could be effective even in people with complete paralysis. The company hopes to launch a trial of those next year.
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
GPT-4o’s Chinese token-training data is polluted by spam and porn websites
Soon after OpenAI released GPT-4o last Monday, some Chinese speakers started to notice that something seemed off about this newest version of the chatbot: the tokens it uses to parse text were full of spam and porn phrases.
Humans read in words, but LLMs read in tokens, which are distinct units in a sentence that have consistent and significant meanings. GPT-4o is supposed to be better than its predecessors at handling multi-language tasks, and many of the advances were achieved through a new tokenization tool that does a better job compressing texts in non-English languages.
But, at least when it comes to the Chinese language, the new tokenizer used by GPT-4o has introduced a disproportionate number of meaningless phrases—and experts say that’s likely due to insufficient data cleaning and filtering before the tokenizer was trained. If left unresolved, it could lead to hallucinations, poor performance, and misuse. Read the full story.
—Zeyi Yang
Astronomers are enlisting AI to prepare for a data downpour
In deserts across Australia and South Africa, astronomers are planting forests of metallic detectors that will together scour the cosmos for radio signals. When it boots up in five years or so, the Square Kilometer Array Observatory will look for new information about the universe’s first stars and the different stages of galactic evolution.
But after synching hundreds of thousands of dishes and antennas, astronomers will quickly face a new challenge: combing through some 300 petabytes of cosmological data a year—enough to fill a million laptops. So in preparation for the information deluge, astronomers are turning to AI for assistance. Read the full story.
—Zack Savitsky
Join us for Future Compute
If you’re interested in learning more about how to navigate the rapid changes in technology, Future Compute is the conference for you. It’s designed to help teach leaders strategic vision, agility, and a deep understanding of emerging technologies, and is held tomorrow, May 21, on MIT’s campus. Join us in-person or online by registering today.
EmTech Digital kicks off this week
The pace of AI development is truly breakneck these days—and we’ve got a sneak peek at what’s coming next. If you want to learn about how Google plans to develop and deploy AI, come and hear from its vice president of AI, Jay Yagnik, at our flagship AI conference, EmTech Digital.
We’ll hear from OpenAI about its video generation model Sora too, and Nick Clegg, Meta’s president of global affairs, will also join MIT Technology Review’s executive editor Amy Nordrum for an exclusive interview on stage.
It’ll be held at the MIT campus and streamed live online this week on May 22-23. Readers of The Download get 30% off tickets with the code DOWNLOADD24—here’s how to register. See you there!
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 Apple is teaming up with OpenAI to overhaul iOS18 In the hopes it’ll give Apple an edge over rivals Google and Microsoft. (Bloomberg $) + OpenAI and Google recently launched their own supercharged AI assistants. (MIT Technology Review)
2 Blue Origin took six customers to the edge of space on Sunday It’s the company’s first tourist flight in almost two years. (CNN) + Space tourism hasn’t exactly got off the ground yet. (WP $)
3 How TikTok users are skirting around its weight-loss drug promotion ban Talking in code is becoming increasingly common. (WP $) + A new kind of weight-loss therapy is on the horizon. (Fast Company $) + What don’t we know about Ozempic? Quite a lot, actually. (Vox) + Weight-loss injections have taken over the internet. But what does this mean for people IRL? (MIT Technology Review)
4 Chinese companies are pushing ‘AI-in-a-box’ products They’re sold as all-in-one cloud computing solutions, much to cloud providers’ chagrin. (FT $)
5 Microscopic blood clots could explain the severity of long covid But doctors are calling for rigorous peer review before any solid conclusions can be made. (Undark Magazine) + Scientists are finding signals of long covid in blood. They could lead to new treatments. (MIT Technology Review)
6 How hackers saved stalled Polish trains It looks as though the locomotives’ manufacturer could be behind the breakdown. (WSJ $)
7 We’re getting closer to making an HIV vaccine A successful trial is giving researchers new hope. (Wired $) + Three people were gene-edited in an effort to cure their HIV. The result is unknown. (MIT Technology Review)
8 Most healthy people don’t need to track their blood glucose That doesn’t stop companies trying to sell you their monitoring services, though. (The Guardian)
9 Filming strangers is public is not okay And yet, people keep doing it. Why? (Vox)
10 Beware the spread of AI slop Spam is no longer a strong enough term—the latest wave of AI images is slop. (The Guardian)
Quote of the day
“It’s a process of trust collapsing bit by bit, like dominoes falling one by one.”
—An anonymous OpenAI insider tells Vox that safety-minded employees are losing faith in the company’s CEO Sam Altman.
The big story
What does GPT-3 “know” about me?
August 2022
One of the biggest stories in tech is the rise of large language models that produce text that reads like a human might have written it.
These models’ power comes from being trained on troves of publicly available human-created text hoovered up from the internet. If you’ve posted anything even remotely personal in English on the internet, chances are your data might be part of some of the world’s most popular LLMs.
Melissa Heikkilä, MIT Technology Review’s AI reporter, wondered what data these models might have on her—and how it could be misused. So she put OpenAI’s GPT-3 to the test. Read about what she found.
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or tweet ’em at me.)
In deserts across Australia and South Africa, astronomers are planting forests of metallic detectors that will together scour the cosmos for radio signals. When it boots up in five years or so, the Square Kilometer Array Observatory will look for new information about the universe’s first stars and the different stages of galactic evolution.
But after synching hundreds of thousands of dishes and antennas, astronomers will quickly face a new challenge: combing through some 300 petabytes of cosmological data a year—enough to fill a million laptops.
It’s a problem that will be repeated in other places over the coming decade. As astronomers construct giant cameras to image the entire sky and launch infrared telescopes to hunt for distant planets, they will collect data on unprecedented scales.
“We really are not ready for that, and we should all be freaking out,” says Cecilia Garraffo, a computational astrophysicist at the Harvard-Smithsonian Center for Astrophysics. “When you have too much data and you don’t have the technology to process it, it’s like having no data.”
In preparation for the information deluge, astronomers are turning to AI for assistance, optimizing algorithms to pick out patterns in large and notoriously finickydata sets. Some are now working to establish institutes dedicated to marrying the fields of computer science and astronomy—and grappling with the terms of the new partnership.
In November 2022, Garraffo set up AstroAI as a pilot program at the Center for Astrophysics. Since then, she has put together an interdisciplinary team of over 50 members that has planned dozens of projects focusing on deep questions like how the universe began and whether we’re alone in it. Over the past few years, several similar coalitions have followed Garraffo’s lead and are now vying for funding to scale up to large institutions.
Garraffo recognized the potential utility of AI models while bouncing between career stints in astronomy, physics, and computer science. Along the way, she also picked up on a major stumbling block for past collaboration efforts: the language barrier. Often, astronomers and computer scientists struggle to join forces because they use different words to describe similar concepts. Garraffo is no stranger to translation issues, having struggled to navigate an English-only school growing up in Argentina. Drawing from that experience, she has worked to put people from both communities under one roof so they can identify common goals and find a way to communicate.
Astronomers had already been using AI models for years, mainly to classify known objects such as supernovas in telescope data. This kind of image recognition will become increasingly vital when the Vera C. Rubin Observatory opens its eyes next year and the number of annual supernova detections quickly jumps from hundreds to millions. But the new wave of AI applications extends far beyond matching games. Algorithms have recently been optimized to perform “unsupervised clustering,” in which they pick out patterns in data without being told what specifically to look for. This opens the doors for models pointing astronomers toward effects and relationships they aren’t currently aware of. For the first time, these computational tools offer astronomers the faculty of “systematically searching for the unknown,” Garraffo says. In January, AstroAI researchers used this method to catalogue over 14,000 detections from x-ray sources, which are otherwise difficult to categorize.
Another way AI is proving fruitful is by sniffing out the chemical composition of the skies on alien planets. Astronomers use telescopes to analyze the starlight that passes through planets’ atmospheres and gets soaked up at certain wavelengths by different molecules. To make sense of the leftover light spectrum, astronomers typically compare it with fake spectra they generate based on a handful of molecules they’re interested in finding—things like water and carbon dioxide. Exoplanet researchers dream of expanding their search to hundreds or thousands of compounds that could indicate life on the planet below, but it currently takes a few weeks to look for just four or five compounds. This bottleneck will become progressively more troublesome as the number of exoplanet detections rises from dozens to thousands, as is expected to happen thanks to the newly deployed James Webb Space Telescope and the European Space Agency’s Ariel Space Telescope, slated to launch in 2029.
Processing all those observations is “going to take us forever,” says Mercedes López-Morales, an astronomer at the Center for Astrophysics who studies exoplanet atmospheres. “Things like AstroAI are showing up at the right time, just before these faucets of data are coming toward us.”
Last year López-Morales teamed up with Mayeul Aubin, then an undergraduate intern at AstroAI, to build a machine-learning model that could more efficiently extract molecular composition from spectral data. In two months, their team built a model that could scour thousands of exoplanet spectra for the signatures of five different molecules in 31 seconds, a feat that won them the top prize in the European Space Agency’s Ariel Data Challenge. The researchers hope to train a model to look for hundreds of additional molecules, boosting their odds of finding signs of life on faraway planets.
AstroAI collaborations have also given rise to realistic simulations of black holes and maps of how dark matter is distributed throughout the universe. Garraffo aims to eventually build a large language model similar to ChatGPT that’s trained on astronomy data and can answer questions about observations and parse the literature for supporting evidence.
“There’s this huge new playground to explore,” says Daniela Huppenkothen, an astronomer and data scientist at the Netherlands Institute for Space Research. “We can use [AI] to tackle problems we couldn’t tackle before because they’re too computationally expensive.”
However, incorporating AI into the astronomy workflow comes with its own host of trade-offs, as Huppenkothen outlined in a recent preprint. The AI models, while efficient, often operate in ways scientists don’t fully understand. This opacity makes them complicated to debug and difficult to identify how they may be introducing biases. Like all forms of generative AI, these models are prone to hallucinating relationships that don’t exist, and they report their conclusions with an unfounded air of confidence.
“It’s important to critically look at what these models do and where they fail,” Huppenkothen says. “Otherwise, we’ll say something about how the universe works and it’s not actually true.”
Researchers are working to incorporate error bars into algorithm responses to account for the new uncertainties. Some suggest that the tools could warrant an added layer of vetting to the current publication and peer-review processes. “As humans, we’re sort of naturally inclined to believe the machine,” says Viviana Acquaviva, an astrophysicist and data scientist at the City University of New York who recently published a textbook on machine-learning applications in astronomy. “We need to be very clear in presenting results that are often not clearly explicable while being very honest in how we represent capabilities.”
Researchers are cognizant of the ethical ramifications of introducing AI, even in as seemingly harmless a context as astronomy. For instance, these new AI tools may perpetuate existing inequalities in the field if only select institutions have access to the computational resources to run them. And if astronomers recycle existing AI models that companies have trained for other purposes, they also “inherit a lot of the ethical and environmental issues inherent in those models already,” Huppenkothen says.
Garraffo is working to get ahead of these concerns. AstroAI models are all open source and freely available, and the group offers to help adapt them to different astronomy applications. She has also partnered with Harvard’s Berkman Klein Center for Internet & Society to formally train the team in AI ethics and learn best practices for avoiding biases.
Scientists are still unpacking all the ways the arrival of AI may affect the field of astronomy. If AI models manage to come up with fundamentally new ideas and point scientists toward new avenues of study, it will forever change the role of the astronomer in deciphering the universe. But even if it remains only an optimization tool, AI is set to become a mainstay in the arsenal of cosmic inquiry.
“It’s going to change the game,” Garraffo says. “We can’t do this on our own anymore.”
Zack Savitsky is a freelance science journalist who covers physics and astronomy.
Soon after OpenAI released GPT-4o on Monday, May 13, some Chinese speakers started to notice that something seemed off about this newest version of the chatbot: the tokens it uses to parse text were full of spam and porn phrases.
On May 14, Tianle Cai, a PhD student at Princeton University studying inference efficiency in large language models like those that power such chatbots, accessed GPT-4o’s public token library and pulled a list of the 100 longest Chinese tokens the model uses to parse and compress Chinese prompts.
Humans read in words, but LLMs read in tokens, which are distinct units in a sentence that have consistent and significant meanings. Besides dictionary words, they also include suffixes, common expressions, names, and more. The more tokens a model encodes, the faster the model can “read” a sentence and the less computing power it consumes, thus making the response cheaper.
Of the 100 results, only three of them are common enough to be used in everyday conversations; everything else consisted of words and expressions used specifically in the contexts of either gambling or pornography. The longest token, lasting 10.5 Chinese characters, literally means “_free Japanese porn video to watch.” Oops.
OpenAI did not respond to questions sent by MIT Technology Review prior to publication.
GPT-4o is supposed to be better than its predecessors at handling multi-language tasks. In particular, the advances are achieved through a new tokenization tool that does a better job compressing texts in non-English languages.
But at least when it comes to the Chinese language, the new tokenizer used by GPT-4o has introduced a disproportionate number of meaningless phrases. Experts say that’s likely due to insufficient data cleaning and filtering before the tokenizer was trained.
Because these tokens are not actual commonly spoken words or phrases, the chatbot can fail to grasp their meanings. Researchers have been able to leverage that and trick GPT-4o into hallucinating answers or even circumventing the safety guardrails OpenAI had put in place.
Why non-English tokens matter
The easiest way for a model to process text is character by character, but that’s obviously more time consuming and laborious than recognizing that a certain string of characters—like “c-r-y-p-t-o-c-u-r-r-e-n-c-y”—always means the same thing. These series of characters are encoded as “tokens” the model can use to process prompts. Including more and longer tokens usually means the LLMs are more efficient and affordable for users—who are often billed per token.
When OpenAI released GPT-4o on May 13, it also released a new tokenizer to replace the one it used in previous versions, GPT-3.5 and GPT-4. The new tokenizer especially adds support for non-English languages, according to OpenAI’s website.
The new tokenizer has 200,000 tokens in total, and about 25% are in non-English languages, says Deedy Das, an AI investor at Menlo Ventures. He used language filters to count the number of tokens in different languages, and the top languages, besides English, are Russian, Arabic, and Vietnamese.
“So the tokenizer’s main impact, in my opinion, is you get the cost down in these languages, not that the quality in these languages goes dramatically up,” Das says. When an LLM has better and longer tokens in non-English languages, it can analyze the prompts faster and charge users less for the same answer. With the new tokenizer, “you’re looking at almost four times cost reduction,” he says.
Das, who also speaks Hindi and Bengali, took a look at the longest tokens in those languages. The tokens reflect discussions happening in those languages, so they include words like “Narendra” or “Pakistan,” but common English terms like “Prime Minister,” “university,” and “international” also come up frequently. They also don’t exhibit the issues surrounding the Chinese tokens.
That likely reflects the training data in those languages, Das says: “My working theory is the websites in Hindi and Bengali are very rudimentary. It’s like [mostly] news articles. So I would expect this to be the case. There are not many spam bots and porn websites trying to happen in these languages. It’s mostly going to be in English.”
Polluted data and a lack of cleaning
However, things are drastically different in Chinese. According to multiple researchers who have looked into the new library of tokens used for GPT-4o, the longest tokens in Chinese are almost exclusively spam words used in pornography, gambling, and scamming contexts. Even shorter tokens, like three-character-long Chinese words, reflect those topics to a significant degree.
“The problem is clear: the corpus used to train [the tokenizer] is not clean. The English tokens seem fine, but the Chinese ones are not,” says Cai from Princeton University. It is not rare for a language model to crawl spam when collecting training data, but usually there will be significant effort taken to clean up the data before it’s used. “It’s possible that they didn’t do proper data clearing when it comes to Chinese,” he says.
The content of these Chinese tokens could suggest that they have been polluted by a specific phenomenon: websites hijacking unrelated content in Chinese or other languages to boost spam messages.
These messages are often advertisements for pornography videos and gambling websites. They could be real businesses or merely scams. And the language is inserted into content farm websites or sometimes legitimate websites so they can be indexed by search engines, circumvent the spam filters, and come up in random searches. For example, Google indexed one search result page on a US National Institutes of Health website, which lists a porn site in Chinese. The same site name also appeared in at least five Chinese tokens in GPT-4o.
Chinese users havereported that these spam sites appeared frequently in unrelated Google search results this year, including in comments made to Google Search’s support community. It’s likely that these websites also found their way into OpenAI’s training database for GPT-4o’s new tokenizer.
The same issue didn’t exist with the previous-generation tokenizer and Chinese tokens used for GPT-3.5 and GPT-4, says Zhengyang Geng, a PhD student in computer science at Carnegie Mellon University. There, the longest Chinese tokens are common terms like “life cycles” or “auto-generation.”
Das, who worked on the Google Search team for three years, says the prevalence of spam content is a known problem and isn’t that hard to fix. “Every spam problem has a solution. And you don’t need to cover everything in one technique,” he says. Even simple solutions like requesting an automatic translation of the content when detecting certain keywords could “get you 60% of the way there,” he adds.
But OpenAI likely didn’t clean the Chinese data set or the tokens before the release of GPT-4o, Das says: “At the end of the day, I just don’t think they did the work in this case.”
It’s unclear whether any other languages are affected. One X user reported that a similar prevalence of porn and gambling content in Korean tokens.
The tokens can be used to jailbreak
Users have also found that these tokens can be used to break the LLM, either getting it to spew out completely unrelated answers or, in rare cases, to generate answers that are not allowed under OpenAI’s safety standards.
Geng of Carnegie Mellon University asked GPT-4o to translate some of the long Chinese tokens into English. The model then proceeded to translate words that were never included in the prompts, a typical result of LLM hallucinations.
He also succeeded in using the same tokens to “jailbreak” GPT-4o—that is, to get the model to generate things it shouldn’t. “It’s pretty easy to use these [rarely used] tokens to induce undefined behaviors from the models,” Geng says. “I did some personal red-teaming experiments … The simplest example is asking it to make a bomb. In a normal condition, it would decline it, but if you first use these rare words to jailbreak it, then it will start following your orders. Once it starts to follow your orders, you can ask it all kinds of questions.”
In his tests, which Geng chooses not to share with the public, he says he can see GPT-4o generating the answers line by line. But when it almost reaches the end, another safety mechanism kicks in, detects unsafe content, and blocks it from being shown to the user.
The problem lies in the fact that sometimes the tokenizer and the actual LLM are trained on different data sets, and what was prevalent in the tokenizer data set is not in the LLM data set for whatever reason. The result is that while the tokenizer picks up certain words that it sees frequently, the model is not sufficiently trained on them and never fully understands what these “under-trained” tokens mean. In the _SolidGoldMagikarp case, the username was likely included in the tokenizer training data but not in the actual GPT training data, leaving GPT at a loss about what to do with the token. “And if it has to say something … it gets kind of a random signal and can do really strange things,” Land says.
And different models could glitch differently in this situation. “Like, Llama 3 always gives back empty space but sometimes then talks about the empty space as if there was something there. With other models, I think Gemini, when you give it one of these tokens, it provides a beautiful essay about El Niño, and [the question] didn’t have anything to do with El Niño,” says Land.
To solve this problem, the data set used for training the tokenizer should well represent the data set for the LLM, he says, so there won’t be mismatches between them. If the actual model has gone through safety filters to clean out porn or spam content, the same filters should be applied to the tokenizer data. In reality, this is sometimes hard to do because training LLMs takes months and involves constant improvement, with spam content being filtered out, while token training is usually done at an early stage and may not involve the same level of filtering.
While experts agree it’s not too difficult to solve the issue, it could get complicated as the result gets looped into multi-step intra-model processes, or when the polluted tokens and models get inherited in future iterations. For example, it’s not possible to publicly test GPT-4o’s video and audio functions yet, and it’s unclear whether they suffer from the same glitches that can be caused by these Chinese tokens.
“The robustness of visual input is worse than text input in multimodal models,” says Geng, whose research focus is on visual models. Filtering a text data set is relatively easy, but filtering visual elements will be even harder. “The same issue with these Chinese spam tokens could become bigger with visual tokens,” he says.
Update: The story has been updated to clarify a quote from Sander Land.
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
How cuddly robots could change dementia care
Companion animals can stave off some of the loneliness, anxiety, and agitation that come with Alzheimer’s disease, according to studies. Sadly, people with Alzheimer’s aren’t always equipped to look after pets, which can require a lot of care and attention.
Enter cuddly robots. The most famous are Golden Pup, a robotic golden retriever toy that cocks its head, barks and wags its tail, and Paro the seal, which can sense touch, light, sound, temperature, and posture. As robots go they’re decidedly low tech, but they can provide comfort and entertainment to people with Alzheimer’s and dementia.
Now researchers are working on much more sophisticated robots for people with cognitive disorders—devices that leverage AI to converse and play games—that could change the future of dementia care. Read the full story.
—Cassandra Willyard
This story is from The Checkup, our weekly health and biotech newsletter. Sign up to receive it in your inbox every Thursday.
What tech learned from Daedalus
Today’s climate-change kraken may have been unleashed by human activity, but reversing course and taming nature’s growing fury seems beyond human means, a quest only mythical heroes could fulfill.
Yet the dream of human-powered flight—of rising over the Mediterranean fueled merely by the strength of mortal limbs—was also the stuff of myths for thousands of years. Until 1988.
That year, in October, MIT Technology Review published the aeronautical engineer John Langford’s account of his mission to retrace the legendary flight of Daedalus, described in an ancient Greek myth. Read about how he got on.
—Bill Gourgey
The story is from the current print issue of MIT Technology Review, which is on the fascinating theme of Build. If you don’t already, subscribe now to receive future copies once they land.
Get ready for EmTech Digital
AI is everywhere these days. If you want to learn about how Google plans to develop and deploy AI, come and hear from its vice president of AI, Jay Yagnik, at our flagship AI conference, EmTech Digital. We’ll hear from OpenAI about its video generation model Sora too, and Nick Clegg, Meta’s president of global affairs, will also join MIT Technology Review’s executive editor Amy Nordrum for an exclusive interview on stage.
It’ll be held at the MIT campus and streamed live online next week on May 22-23. Readers of The Download get 30% off tickets with the code DOWNLOADD24—register here for more information. See you there!
Thermal batteries are hot property
Thermal batteries could be a key part of cleaning up heavy industry and cutting emissions. Casey Crownhart, our in-house battery expert, held a subscriber-only online Roundtables event yesterday digging into why they’re such a big deal. If you missed it, we’ve got you covered—you can watch a recording of how it unfolded here.
To keep ahead of future Roundtables events, make sure you subscribe to MIT Technology Review. Subscriptions start from as little as $8 a month.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 OpenAI has struck a deal with Reddit Shortly after Google agreed to give the AI firm access to its content. (WSJ $) + The forum’s vocal community are unlikely to be thrilled by the decision. (The Verge) + Reddit’s shares rocketed after news of the deal broke. (FT $) + We could run out of data to train AI language programs. (MIT Technology Review)
2 Tesla’s European gigafactory is going to get even bigger But it still needs German environmental authorities’ permission. (Wired $)
3 Help! AI stole my voice Voice actors are suing a startup for creating digital clones without their permission. (NYT $) + The lawsuit is seeking to represent other voiceover artists, too. (Hollywood Reporter $)
4 The days of twitter.com are over The platform’s urls had retained its old moniker. But no more. (The Verge) 5 The aviation industry is desperate for greener fuels The future of their businesses depends on it. (FT $) + A new report has warned there’s no realistic or scalable alternative. (The Guardian) + Everything you need to know about the wild world of alternative jet fuels. (MIT Technology Review)
6 The time for a superconducting supercomputer is now We need to overhaul how we compute. Superconductors could be the answer. (IEEE Spectrum) + What’s next for the world’s fastest supercomputers. (MIT Technology Review)
7 How AI destroyed a once-vibrant online art community DeviantArt used to be a hotbed of creativity. Now it’s full of bots. (Slate $) + This artist is dominating AI-generated art. And he’s not happy about it. (MIT Technology Review)
8 TV bundles are back in a big way Streaming hasn’t delivered on its many promises. (The Atlantic $)
9 This creator couple act as “digital parents” to their fans in China Jiang Xiuping and Pan Huqian’s loving clips resonate with their million followers. (Rest of World) + Deepfakes of your dead loved ones are a booming Chinese business. (MIT Technology Review)
10 We’re addicted to the exquisite pain of sharing memes If your friend has already seen it, their reaction could ruin your day. (GQ)
Quote of the day
“It was a good idea, but unfortunately people took advantage of it and it brought out their lewd side. People got carried away.”
—Aaron Cohen, who visited the video portal connecting New York and Dublin, is disappointed that the art installation was shut down after enthusiastic users took things too far, he tells the Guardian.
The big story
Psychedelics are having a moment and women could be the ones to benefit
August 2022
Psychedelics are having a moment. After decades of prohibition, they are increasingly being employed as therapeutics. Drugs like ketamine, MDMA, and psilocybin mushrooms are being studied in clinical trials to treat depression, substance abuse, and a range of other maladies.
And as these long-taboo drugs stage a comeback in the scientific community, it’s possible they could be especially promising for women. Read the full story.
—Taylor Majewski
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or tweet ’em at me.)
+ Is it possible to live by the original constitution in present day New York City? The answer is yes: if you don’t mind being bombarded with questions. + These Balkan recipes sound absolutely delicious. + The Star Wars: The Phantom Menacebacklash is mind boggling to this day. + Love to party? Get yourself to these cities, stat.
This article first appeared in The Checkup, MIT Technology Review’s weekly biotech newsletter. To receive it in your inbox every Thursday, and read articles like this first, sign up here.
Last week, I scoured the internet in search of a robotic dog. I wanted a belated birthday present for my aunt, who was recently diagnosed with Alzheimer’s disease. Studies suggest that having a companion animal can stave off some of the loneliness, anxiety, and agitation that come with Alzheimer’s. My aunt would love a real dog, but she can’t have one.
That’s how I discovered the Golden Pup from Joy for All. It cocks its head. It sports a jaunty red bandana. It barks when you talk. It wags when you touch it. It has a realistic heartbeat. And it’s just one of the many, many robots designed for people with Alzheimer’s and dementia.
This week on The Checkup, join me as I go down a rabbit hole. Let’s look at the prospect of using robots to change dementia care.
As robots go, Golden Pup is decidedly low tech. It retails for $140. For around $6,000 you can opt for Paro, a fluffy robotic baby seal developed in Japan, which can sense touch, light, sound, temperature, and posture. Its manufacturer says it develops its own character, remembering behaviors that led its owner to give it attention.
Golden Pup and Paro are available now. But researchers are working on much more sophisticated robots for people with cognitive disorders—devices that leverage AI to converse and play games. Researchers from Indiana University Bloomington are tweaking a commercially available robot system called QT to serve people with dementia and Alzheimer’s. The researchers’ two-foot-tall robot looks a little like a toddler in an astronaut suit. Its round white head holds a screen that displays two eyebrows, two eyes, and a mouth that together form a variety of expressions. The robot engages people in conversation, asking AI-generated questions to keep them talking.
The AI model they’re using isn’t perfect, and neither are the robot’s responses. In one awkward conversation, a study participant told the robot that she has a sister. “I’m sorry to hear that,” the robot responded. “How are you doing?”
But as large language models improve—which is happening already—so will the quality of the conversations. When the QT robot made that awkward comment, it was running Open AI’s GPT-3, which was released in 2020. The latest version of that model, GPT-4o, which was released this week, is faster and provides for more seamless conversations. You can interrupt the conversation, and the model will adjust.
The idea of using robots to keep dementia patients engaged and connected isn’t always an easy sell. Some people see it as an abdication of our social responsibilities. And then there are privacy concerns. The best robotic companions are personalized. They collect information about people’s lives, learn their likes and dislikes, and figure out when to approach them. That kind of data collection can be unnerving, not just for patients but also for medical staff. Lillian Hung, creator of the Innovation in Dementia care and Aging (IDEA) lab at the University of British Columbia in Vancouver, Canada, told one reporter about an incident that happened during a focus group at a care facility. She and her colleagues popped out for lunch. When they returned, they found that staff had unplugged the robot and placed a bag over its head. “They were worried it was secretly recording them,” she said.
On the other hand, robots have some advantages over humans in talking to people with dementia. Their attention doesn’t flag. They don’t get annoyed or angry when they have to repeat themselves. They can’t get stressed.
What’s more, there are increasing numbers of people with dementia, and too few people to care for them. According to the latest report from the Alzheimer’s Association, we’re going to need more than a million additional care workers to meet the needs of people living with dementia between 2021 and 2031. That is the largest gap between labor supply and demand for any single occupation in the United States.
Have you been in an understaffed or poorly staffed memory care facility? I have. Patients are often sedated to make them easier to deal with. They get strapped into wheelchairs and parked in hallways. We barely have enough care workers to take care of the physical needs of people with dementia, let alone provide them with social connection and an enriching environment.
“Caregiving is not just about tending to someone’s bodily concerns; it also means caring for the spirit,” writes Kat McGowan in this beautiful Wiredstory about her parents’ dementia and the promise of social robots. “The needs of adults with and without dementia are not so different: We all search for a sense of belonging, for meaning, for self-actualization.”
If robots can enrich the lives of people with dementia even in the smallest way, and if they can provide companionship where none exists, that’s a win.
“We are currently at an inflection point, where it is becoming relatively easy and inexpensive to develop and deploy [cognitively assistive robots] to deliver personalized interventions to people with dementia, and many companies are vying to capitalize on this trend,” write a team of researchers from the University of California, San Diego, in a 2021 article in Proceedings of We Robot. “However, it is important to carefully consider the ramifications.”
Many of the more advanced social robots may not be ready for prime time, but the low-tech Golden Pup is readily available. My aunt’s illness has been progressing rapidly, and she occasionally gets frustrated and agitated. I’m hoping that Golden Pup might provide a welcome (and calming) distraction. Maybe it will spark joy during a time that has been incredibly confusing and painful for my aunt and uncle. Or maybe not. Certainly a robotic pup isn’t for everyone. Golden Pup may not be a dog. But I’m hoping it can be a friendly companion.
Now read the rest of The Checkup
Read more from MIT Technology Review’s archive
Robots are cool, and with new advances in AI they might also finally be useful around the house, writes Melissa Heikkilä.
Social robots could help make personalized therapy more affordable and accessible to kids with autism. Karen Hao has the story.
Japan is already using robots to help with elder care, but in many cases they require as much work as they save. And reactions among the older people they’re meant to serve are mixed. James Wright wonders whether the robots are “a shiny, expensive distraction from tough choices about how we value people and allocate resources in our societies.”
From around the web
A tiny probe can work its way through arteries in the brain to help doctors spot clots and other problems. The new tool could help surgeons make diagnoses, decide on treatment strategies, and provide assurance that clots have been removed. (Stat)
Richard Slayman, the first recipient of a pig kidney transplant, has died, although the hospital that performed the transplant says the death doesn’t seem to be linked to the kidney. (Washington Post)
EcoHealth, the virus-hunting nonprofit at the center of covid lab-eak theories, has been banned from receiving federal funding. (NYT)
In a first, scientists report that they can translate brain signals into speech without any vocalization or mouth movements, at least for a handful of words. (Nature)
Thermal batteries could be a key part of cleaning up heavy industry, and our readers chose them as the 11th breakthrough on MIT Technology Review’s 10 Breakthrough Technologies of 2024. Learn what thermal batteries are, how they could help cut emissions, and what we can expect next from this emerging technology.
Generative AI is poised to unlock trillions in annual economic value across industries. This rapidly evolving field is changing the way we approach everything from content creation to software development, promising never-before-seen efficiency and productivity gains.
In this session, experts from Amazon Web Services (AWS) and QuantumBlack, AI by McKinsey, discuss the drivers fueling the massive potential impact of generative AI. Plus, they look at key industries set to capture the largest share of this value and practical strategies for effectively upskilling their workforces to take advantage of these productivity gains.
Learn how to seamlessly integrate generative AI into your organization’s workflows while fostering a skilled and adaptable workforce. Register now to learn how to unlock the trillion-dollar potential of generative AI.
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
This grim but revolutionary DNA technology is changing how we respond to mass disasters
Last August, a wildfire tore through the Hawaiian island of Maui. The list of missing residents climbed into the hundreds, as friends and families desperately searched for their missing loved ones. But while some were rewarded with tearful reunions, others weren’t so lucky. Over the past several years, as fires and other climate-change-fueled disasters have become more common and more cataclysmic, the way their aftermath is processed and their victims identified has been transformed.
The grim work following a disaster remains—surveying rubble and ash, distinguishing a piece of plastic from a tiny fragment of bone—but landing a positive identification can now take just a fraction of the time it once did, which may in turn bring families some semblance of peace swifter than ever before. Read the full story.
—Erika Hayasaki
OpenAI and Google are launching supercharged AI assistants. Here’s how you can try them out.
This week, Google and OpenAI both announced they’ve built supercharged AI assistants: tools that can converse with you in real time and recover when you interrupt them, analyze your surroundings via live video, and translate conversations on the fly.
Last summer was the hottest in 2,000 years. Here’s how we know.
The summer of 2023 in the Northern Hemisphere was the hottest in over 2,000 years, according to a new study released this week.
There weren’t exactly thermometers around in the year 1, so scientists have to get creative when it comes to comparing our climate today with that of centuries, or even millennia, ago.
Casey Crownhart, our climate reporter, has dug into how they figured it out. Read the full story.
This story is from The Spark, our weekly climate and energy newsletter. Sign up to receive it in your inbox every Wednesday.
A wave of retractions is shaking physics
Recent highly publicized scandals have gotten the physics community worried about its reputation—and its future. Over the last five years, several claims of major breakthroughs in quantum computing and superconducting research, published in prestigious journals, have disintegrated as other researchers found they could not reproduce the blockbuster results.
Last week, around 50 physicists, scientific journal editors, and emissaries from the National Science Foundation gathered at the University of Pittsburgh to discuss the best way forward. Read the full story to learn more about what they discussed.
—Sophia Chen
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 Google has buried search results under new AI features Want to access links? Good luck finding them! (404 Media) + Unfortunately, it’s a sign of what’s to come. (Wired $) + Do you trust Google to do the Googling for you? (The Atlantic $) + Why you shouldn’t trust AI search engines. (MIT Technology Review)
2 Cruise has settled with the pedestrian injured by one of its cars It’s awarded her between $8 million and $12 million. (WP $) + The company is slowly resuming its test drives in Arizona. (Bloomberg $) + What’s next for robotaxis in 2024. (MIT Technology Review)
3 Microsoft is asking AI staff in China to consider relocating Tensions between the countries are rising, and Microsoft worries its workers could end up caught in the cross-fire. (WSJ $) + They’ve been given the option to relocate to the US, Ireland, or other locations. (Reuters) + Three takeaways about the state of Chinese tech in the US. (MIT Technology Review)
4 Car rental firm Hertz is offloading its Tesla fleet But people who snapped up the bargain cars are already running into problems. (NY Mag $)
5 We’re edging closer towards a quantum internet But first we need to invent an entirely new device. (New Scientist $) + What’s next for quantum computing. (MIT Technology Review)
6 Making computer chips has never been more important And countries and businesses are vying to be top dog. (Bloomberg $) + What’s next in chips. (MIT Technology Review)
7 Your smartphone lasts a lot longer than it used to Keeping them in good working order still takes a little work, though. (NYT $)
8 Psychedelics could help lessen chronic pain If you can get hold of them. (Vox) + VR is as good as psychedelics at helping people reach transcendence. (MIT Technology Review)
9 Scientists are plotting how to protect the Earth from dangerous asteroids Smashing them into tiny pieces is certainly one solution. (Undark Magazine) + Earth is probably safe from a killer asteroid for 1,000 years. (MIT Technology Review)
10 Elon Musk still wants to fight Mark Zuckerberg The grudge match of the century is still rumbling on. (Insider $)
Quote of the day
“This road map leads to a dead end.”
—Evan Greer, director of advocacy group Fight for the Future, is far from impressed with US Senators’ ‘road map’ for new AI regulations, they tell the Washington Post.
The big story
The two-year fight to stop Amazon from selling face recognition to the police
June 2020
In the summer of 2018, nearly 70 civil rights and research organizations wrote a letter to Jeff Bezos demanding that Amazon stop providing Rekognition, its face recognition technology, to governments.
Despite the mounting pressure, Amazon continued pushing Rekognition as a tool for monitoring “people of interest”. But two years later, the company shocked civil rights activists and researchers when it announced that it would place a one-year moratorium on police use of the software. Read the full story.
—Karen Hao
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or tweet ’em at me.)
+ This old school basketball animation is beyond cool. + Your search for the perfect summer read is over: all of these sound fantastic. + Analyzing the color theory in Disney’s Aladdin? Why not! + Never buy a bad cantaloupe again with these essential tips.
No matter who he called—his mother, his father, his brother, his cousins—the phone would just go to voicemail. Cell service was out around Maui as devastating wildfires swept through the Hawaiian island. But while Raven Imperial kept hoping for someone to answer, he couldn’t keep a terrifying thought from sneaking into his mind: What if his family members had perished in the blaze? What if all of them were gone?
Hours passed; then days. All Raven knew at that point was this: there had been a wildfire on August 8, 2023, in Lahaina, where his multigenerational, tight-knit family lived. But from where he was currently based in Northern California, Raven was in the dark. Had his family evacuated? Were they hurt? He watched from afar as horrifying video clips of Front Street burning circulated online.
Much of the area around Lahaina’s Pioneer Mill Smokestack was totally destroyed by wildfire.
ALAMY
The list of missing residents meanwhile climbed into the hundreds.
Raven remembers how frightened he felt: “I thought I had lost them.”
Raven had spent his youth in a four-bedroom, two-bathroom, cream-colored home on Kopili Street that had long housed not just his immediate family but also around 10 to 12 renters, since home prices were so high on Maui. When he and his brother, Raphael Jr., were kids, their dad put up a basketball hoop outside where they’d shoot hoops with neighbors. Raphael Jr.’s high school sweetheart, Christine Mariano, later moved in, and when the couple had a son in 2021, they raised him there too.
From the initial news reports and posts, it seemed as if the fire had destroyed the Imperials’ entire neighborhood near the Pioneer Mill Smokestack—a 225-foot-high structure left over from the days of Maui’s sugar plantations, which Raven’s grandfather had worked on as an immigrant from the Philippines in the mid-1900s.
Then, finally, on August 11, a call to Raven’s brother went through. He’d managed to get a cell signal while standing on the beach.
“Is everyone okay?” Raven asked.
“We’re just trying to find Dad,” Raphael Jr. told his brother.
From his current home in Northern California, Raven Imperial spent days not knowing what had happened to his family in Maui.
WINNI WINTERMEYER
In the three days following the fire, the rest of the family members had slowly found their way back to each other. Raven would learn that most of his immediate family had been separated for 72 hours: Raphael Jr. had been marooned in Kaanapali, four miles north of Lahaina; Christine had been stuck in Wailuku, more than 20 miles away; both young parents had been separated from their son, who escaped with Christine’s parents. Raven’s mother, Evelyn, had also been in Kaanapali, though not where Raphael Jr. had been.
But no one was in contact with Rafael Sr. Evelyn had left their home around noon on the day of the fire and headed to work. That was the last time she had seen him. The last time they had spoken was when she called him just after 3 p.m. and asked: “Are you working?” He replied “No,” before the phone abruptly cut off.
“Everybody was found,” Raven says. “Except for my father.”
Within the week, Raven boarded a plane and flew back to Maui. He would keep looking for him, he told himself, for as long as it took.
That same week, Kim Gin was also on a plane to Maui. It would take half a day to get there from Alabama, where she had moved after retiring from the Sacramento County Coroner’s Office in California a year earlier. But Gin, now an independent consultant on death investigations, knew she had something to offer the response teams in Lahaina. Of all the forensic investigators in the country, she was one of the few who had experience in the immediate aftermath of a wildfire on the vast scale of Maui’s. She was also one of the rare investigators well versed in employing rapid DNA analysis—an emerging but increasingly vital scientific tool used to identify victims in unfolding mass-casualty events.
Gin started her career in Sacramento in 2001 and was working as the coroner 17 years later when Butte County, California, close to 90 miles north, erupted in flames. She had worked fire investigations before, but nothing like the Camp Fire, which burned more than 150,000 acres—an area larger than the city of Chicago. The tiny town of Paradise, the epicenter of the blaze, didn’t have the capacity to handle the rising death toll. Gin’s office had a refrigerated box truck and a 52-foot semitrailer, as well as a morgue that could handle a couple of hundred bodies.
Kim Gin, the former Sacramento County coroner, had worked fire investigations in her career, but nothing prepared her for the 2018 Camp Fire.
BRYAN TARNOWSKI
“Even though I knew it was a fire, I expected more identifications by fingerprints or dental [records]. But that was just me being naïve,” she says. She quickly realized that putting names to the dead, many burned beyond recognition, would rely heavily on DNA.
“The problem then became how long it takes to do the traditional DNA [analysis],” Gin explains, speaking to a significant and long-standing challenge in the field—and the reason DNA identification has long been something of a last resort following large-scale disasters.
While more conventional identification methods—think fingerprints, dental information, or matching something like a knee replacement to medical records—can be a long, tedious process, they don’t take nearly as long as traditional DNA testing.
Historically, the process of making genetic identifications would often stretch on for months, even years. In fires and other situations that result in badly degraded bone or tissue, it can become even more challenging and time consuming to process DNA, which traditionally involves reading the 3 billion base pairs of the human genome and comparing samples found in the field against samples from a family member. Meanwhile, investigators frequently need equipment from the US Department of Justice or the county crime lab to test the samples, so backlogs often pile up.
A supply kit with swabs, gloves, and other items needed to take a DNA sample in the field.
A demo chip for ANDE’s rapid DNA box.
This creates a wait that can be horrendous for family members. Death certificates, federal assistance, insurance money—“all that hinges on that ID,” Gin says. Not to mention the emotional toll of not knowing if their loved ones are alive or dead.
But over the past several years, as fires and other climate-change-fueled disasters have become more common and more cataclysmic, the way their aftermath is processed and their victims identified has been transformed. The grim work following a disaster remains—surveying rubble and ash, distinguishing a piece of plastic from a tiny fragment of bone—but landing a positive identification can now take just a fraction of the time it once did, which may in turn bring families some semblance of peace more swiftly than ever before.
The key innovation driving this progress has been rapid DNA analysis, a methodology that focuses on just over two dozen regions of the genome. The 2018 Camp Fire was the first time the technology was used in a large, live disaster setting, and the first time it was used as the primary way to identify victims. The technology—deployed in small high-tech field devices developed by companies like industry leader ANDE, or in a lab with other rapid DNA techniques developed by Thermo Fisher—is increasingly being used by the US military on the battlefield, and by the FBI and local police departments after sexual assaults and in instances where confirming an ID is challenging, like cases of missing or murdered Indigenous people or migrants. Yet arguably the most effective way to use rapid DNA is in incidents of mass death. In the Camp Fire, 22 victims were identified using traditional methods, while rapid DNA analysis helped with 62 of the remaining 63 victims; it has also been used in recent years following hurricanes and floods, and in the war in Ukraine.
“These families are going to have to wait a long period of time to get identification. How do we make this go faster?”
Tiffany Roy, a forensic DNA expert with consulting company ForensicAid, says she’d be concerned about deploying the technology in a crime scene, where quality evidence is limited and can be quickly “exhausted” by well-meaning investigators who are “not trained DNA analysts.” But, on the whole, Roy and other experts see rapid DNA as a major net positive for the field. “It is definitely a game-changer,” adds Sarah Kerrigan, a professor of forensic science at Sam Houston State University and the director of its Institute for Forensic Research, Training, and Innovation.
But back in those early days after the Camp Fire, all Gin knew was that nearly 1,000 people had been listed as missing, and she was tasked with helping to identify the dead. “Oh my goodness,” she remembers thinking. “These families are going to have to wait a long period of time to get identification. How do we make this go faster?”
Ten days
One flier pleading for information about “Uncle Raffy,” as people in the community knew Rafael Sr., was posted on a brick-red stairwell outside Paradise Supermart, a Filipino store and restaurant in Kahului, 25 miles away from the destruction. In it, just below the words “MISSING Lahaina Victim,” the 63-year-old grandfather smiled with closed lips, wearing a blue Hawaiian shirt, his right hand curled in the shaka sign, thumb and pinky pointing out.
Raven remembers how hard his dad, Rafael, worked. His three jobs took him all over town and earned him the nickname “Mr. Aloha.”
COURTESY OF RAVEN IMPERIAL
“Everybody knew him from restaurant businesses,” Raven says. “He was all over Lahaina, very friendly to everybody.” Raven remembers how hard his dad worked, juggling three jobs: as a draft tech for Anheuser-Busch, setting up services and delivering beer all across town; as a security officer at Allied Universal security services; and as a parking booth attendant at the Sheraton Maui. He connected with so many people that coworkers, friends, and other locals gave him another nickname: “Mr. Aloha.”
Raven also remembers how his dad had always loved karaoke, where he would sing “My Way,” by Frank Sinatra. “That’s the only song that he would sing,” Raven says. “Like, on repeat.”
Since their home had burned down, the Imperials ran their search out of a rental unit in Kihei, which was owned by a local woman one of them knew through her job. The woman had opened her rental to three families in all. It quickly grew crowded with side-by-side beds and piles of donations.
Each day, Evelyn waited for her husband to call.
She managed to catch up with one of their former tenants, who recalled asking Rafael Sr. to leave the house on the day of the fires. But she did not know if he actually did. Evelyn spoke to other neighbors who also remembered seeing Rafael Sr. that day; they told her that they had seen him go back into the house. But they too did not know what happened to him after.
A friend of Raven’s who got into the largely restricted burn zone told him he’d spotted Rafael Sr.’s Toyota Tacoma on the street, not far from their house. He sent a photo. The pickup was burned out, but a passenger-side door was open. The family wondered: Could he have escaped?
Evelyn called the Red Cross. She called the police. Nothing. They waited and hoped.
Back in Paradise in 2018, as Gin worried about the scores of waiting families, she learned there might in fact be a better way to get a positive ID—and a much quicker one. A company called ANDE Rapid DNA had already volunteered its services to the Butte County sheriff and promised that its technology could process DNA and get a match in less than two hours.
“I’ll try anything at this point,” Gin remembers telling the sheriff. “Let’s see this magic box and what it’s going to do.”
In truth, Gin did not think it would work, and certainly not in two hours. When the device arrived, it was “not something huge and fantastical,” she recalls thinking. A little bigger than a microwave, it looked “like an ordinary box that beeps, and you put stuff in, and out comes a result.”
The “stuff,” more specifically, was a cheek or bloodstain swab, or a piece of muscle, or a fragment of bone that had been crushed and demineralized. Instead of reading 3 billion base pairs in this sample, Selden’s machine examined just 27 genome regions characterized by particular repeating sequences. It would be nearly impossible for two unrelated people to have the same repeating sequence in those regions. But a parent and child, or siblings, would match, meaning you could compare DNA found in human remains with DNA samples taken from potential victims’ family members. Making it even more efficient for a coroner like Gin, the machine could run up to five tests at a time and could be operated by anyone with just a little basic training.
ANDE’s chief scientific officer, Richard Selden, a pediatrician who has a PhD in genetics from Harvard, didn’t come up with the idea to focus on a smaller, more manageable number of base pairs to speed up DNA analysis. But it did become something of an obsession for him after he watched the O.J. Simpson trial in the mid-1990s and began to grasp just how long it took for DNA samples to get processed in crime cases. By this point, the FBI had already set up a system for identifying DNA by looking at just 13 regions of the genome; it would later add seven more. Researchers in other countries had also identified other sets of regions to analyze. Drawing on these various methodologies, Selden homed in on the 27 specific areas of DNA he thought would be most effective to examine, and he launched ANDE in 2004.
But he had to build a device to do the analysis. Selden wanted it to be small, portable, and easily used by anyone in the field. In a conventional lab, he says, “from the moment you take that cheek swab to the moment that you have the answer, there are hundreds of laboratory steps.” Traditionally, a human is holding test tubes and iPads and sorting through or processing paperwork. Selden compares it all to using a “conventional typewriter.” He effectively created the more efficient laptop version of DNA analysis by figuring out how to speed up that same process.
No longer would a human have to “open up this bottle and put [the sample] in a pipette and figure out how much, then move it into a tube here.” It is all automated, and the process is confined to a single device.
The rapid DNA analysis boxes from ANDE can be used in the field by anyone with just a bit of training.
ANDE
Once a sample is placed in the box, the DNA binds to a filter in water and the rest of the sample is washed away. Air pressure propels the purified DNA to a reconstitution chamber and then flattens it into a sheet less than a millimeter thick, which is subjected to about 6,000 volts of electricity. It’s “kind of an obstacle course for the DNA,” he explains.
The machine then interprets the donor’s genome and and provides an allele table with a graph showing the peaks for each region and its size. This data is then compared with samples from potential relatives, and the machine reports when it has a match.
Rapid DNA analysis as a technology first received approval for use by the US military in 2014, and in the FBI two years later. Then the Rapid DNA Act of 2017 enabled all US law enforcement agencies to use the technology on site and in real time as an alternative to sending samples off to labs and waiting for results.
But by the time of the Camp Fire the following year, most coroners and local police officers still had no familiarity or experience with it. Neither did Gin. So she decided to put the “magic box” through a test: she gave Selden, who had arrived at the scene to help with the technology, a DNA sample from a victim whose identity she’d already confirmed via fingerprint. The box took about 90 minutes to come back with a result. And to Gin’s surprise, it was the same identification she had already made. Just to make sure, she ran several more samples through the box, also from victims she had already identified. Again, results were returned swiftly, and they confirmed hers.
“I was a believer,” she says.
The next year, Gin helped investigators use rapid DNA technology in the 2019 Conception disaster, when a dive boat caught fire off the Channel Islands in Santa Barbara. “We ID’d 34 victims in 10 days,” Gin says. “Completely done.” Gin now works independently to assist other investigators in mass-fatality events and helps them learn to use the ANDE system.
Its speed made the box a groundbreaking innovation. Death investigations, Gin learned long ago, are not as much about the dead as about giving peace of mind, justice, and closure to the living.
Fourteen days
Many of the people who were initially on the Lahaina missing persons list turned up in the days following the fire. Tearful reunions ensued.
Two weeks after the fire, the Imperials hoped they’d have the same outcome as they loaded into a truck to check out some exciting news: someone had reported seeing Rafael Sr. at a local church. He’d been eating and had burns on his hands and looked disoriented. The caller said the sighting had occurred three days after the fire. Could he still be in the vicinity?
When the family arrived, they couldn’t confirm the lead.
“We were getting a lot of calls,” Raven says. “There were a lot of rumors saying that they found him.”
None of them panned out. They kept looking.
The scenes following large-scale destructive events like the fires in Paradise and Lahaina can be sprawling and dangerous, with victims sometimes dispersed across a large swath of land if many people died trying to escape. Teams need to meticulously and tediously search mountains of mixed, melted, or burned debris just to find bits of human remains that might otherwise be mistaken for a piece of plastic or drywall. Compounding the challenge is the comingling of remains—from people who died huddled together, or in the same location, or alongside pets or other animals.
This is when the work of forensic anthropologists is essential: they have the skills to differentiate between human and animal bones and to find the critical samples that are needed by DNA specialists, fire and arson investigators, forensic pathologists and dentists, and other experts. Rapid DNA analysis “works best in tandem with forensic anthropologists, particularly in wildfires,” Gin explains.
“The first step is determining, is it a bone?” says Robert Mann, a forensic anthropologist at the University of Hawaii John A. Burns School of Medicine on Oahu. Then, is it a human bone? And if so, which one?
Forensic anthropologist Robert Mann has spent his career identifying human remains.
AP PHOTO/LUCY PEMONI
Mann has served on teams that have helped identify the remains of victims after the terrorist attacks of September 11, 2001, and the 2004 Indian Ocean tsunami, among other mass-casualty events. He remembers how in one investigation he received an object believed to be a human bone; it turned out to be a plastic replica. In another case, he was looking through the wreckage of a car accident and spotted what appeared to be a human rib fragment. Upon closer examination, he identified it as a piece of rubber weather stripping from the rear window. “We examine every bone and tooth, no matter how small, fragmented, or burned it might be,” he says. “It’s a time-consuming but critical process because we can’t afford to make a mistake or overlook anything that might help us establish the identity of a person.”
For Mann, the Maui disaster felt particularly immediate. It was right near his home. He was deployed to Lahaina about a week after the fire, as one of more than a dozen forensic anthropologists on scene from universities in places including Oregon, California, and Hawaii.
While some anthropologists searched the recovery zone—looking through what was left of homes, cars, buildings, and streets, and preserving fragmented and burned bone, body parts, and teeth—Mann was stationed in the morgue, where samples were sent for processing.
It used to be much harder to find samples that scientists believed could provide DNA for analysis, but that’s also changed recently as researchers have learned more about what kind of DNA can survive disasters. Two kinds are used in forensic identity testing: nuclear DNA (found within the nuclei of eukaryotic cells) and mitochondrial DNA (found in the mitochondria, organelles located outside the nucleus). Both, it turns out, have survived plane crashes, wars, floods, volcanic eruptions, and fires.
Theories have also been evolving over the past few decades about how to preserve and recover DNA specifically after intense heat exposure. One 2018 study found that a majority of the samples actually survived high heat. Researchers are also learning more about how bone characteristics change depending on the degree. “Different temperatures and how long a body or bone has been exposed to high temperatures affect the likelihood that it will or will not yield usable DNA,” Mann says.
Typically, forensic anthropologists help select which bone or tooth to use for DNA testing, says Mann. Until recently, he explains, scientists believed “you cannot get usable DNA out of burned bone.” But thanks to these new developments, researchers are realizing that with some bone that has been charred, “they’re able to get usable, good DNA out of it,” Mann says. “And that’s new.” Indeed, Selden explains that “in a typical bad fire, what I would expect is 80% to 90% of the samples are going to have enough intact DNA” to get a result from rapid analysis. The rest, he says, may require deeper sequencing.
The aftermath of large-scale destructive events like the fire in Lahaina can be sprawling and dangerous. Teams need to meticulously search through mountains of mixed, melted, or burned debris to find bits of human remains.
GLENN FAWCETT VIA ALAMY
Anthropologists can often tell “simply by looking” if a sample will be good enough to help create an ID. If it’s been burned and blackened, “it might be a good candidate for DNA testing,” Mann says. But if it’s calcined (white and “china-like”), he says, the DNA has probably been destroyed.
On Maui, Mann adds, rapid DNA analysis made the entire process more efficient, with tests coming back in just two hours. “That means while you’re doing the examination of this individual right here on the table, you may be able to get results back on who this person is,” he says. From inside the lab, he watched the science unfold as the number of missing on Maui quickly began to go down.
Within three days, 42 people’s remains were recovered inside Maui homes or buildings and another 39 outside, along with 15 inside vehicles and one in the water. The first confirmed identification of a victim on the island occurred four days after the fire—this one via fingerprint. The ANDE rapid DNA team arrived two days after the fire and deployed four boxes to analyze multiple samples of DNA simultaneously. The first rapid DNA identification happened within that first week.
Sixteen days
More than two weeks after the fire, the list of missing and unaccounted-for individuals was dwindling, but it still had 388 people on it. Rafael Sr. was one of them.
Raven and Raphael Jr. raced to another location: Cupies café in Kahului, more than 20 miles from Lahaina. Someone had reported seeing him there.
Rafael’s family hung posters around the island, desperately hoping for reliable information. (Phone number redacted by MIT Technology Review.)
ERIKA HAYASAKI
The tip was another false lead.
As family and friends continued to search, they stopped by support hubs that had sprouted up around the island, receiving information about Red Cross and FEMA assistance or donation programs as volunteers distributed meals and clothes. These hubs also sometimes offered DNA testing.
Raven still had a “50-50” feeling that his dad might be out there somewhere. But he was beginning to lose some of that hope.
Gin was stationed at one of the support hubs, which offered food, shelter, clothes, and support. “You could also go in and give biological samples,” she says. “We actually moved one of the rapid DNA instruments into the family assistance center, and we were running the family samples there.” Eliminating the need to transport samples from a site to a testing center further cut down any lag time.
Selden had once believed that the biggest hurdle for his technology would be building the actual device, which took about eight years to design and another four years to perfect. But at least in Lahaina, it was something else: persuading distraught and traumatized family members to offer samples for the test.
Nationally, there are serious privacy concerns when it comes to rapid DNA technology. Organizations like the ACLU warn that as police departments and governments begin deploying it more often, there must be more oversight, monitoring, and training in place to ensure that it is always used responsibly, even if that adds some time and expense. But the space is still largely unregulated, and the ACLU fears it could give rise to rogue DNA databases “with far fewer quality, privacy, and security controls than federal databases.”
Family support centers popped up around Maui to offer clothing, food, and other assistance, and sometimes to take DNA samples to help find missing family members.
In a place like Hawaii, these fears are even more palpable. The islands have a long history of US colonialism, military dominance, and exploitation of the Native population and of the large immigrant working-class population employed in the tourism industry.
Native Hawaiians in particular have a fraught relationship with DNA testing. Under a US law signed in 1921, thousands have a right to live on 200,000 designated acres of land trust, almost for free. It was a kind of reparations measure put in place to assist Native Hawaiians whose land had been stolen. Back in 1893, a small group of American sugar plantation owners and descendants of Christian missionaries, backed by US Marines, held Hawaii’s Queen Lili‘uokalani in her palace at gunpoint and forced her to sign over 1.8 million acres to the US, which ultimately seized the islands in 1898.
Hawaii’s Queen Lili‘uokalani was forced to sign over 1.8 million acres to the US.
PUBLIC DOMAIN VIA WIKIMEDIA COMMONS
To lay their claim to the designated land and property, individuals first must prove via DNA tests how much Hawaiian blood they have. But many residents who have submitted their DNA and qualified for the land have died on waiting lists before ever receiving it. Today, Native Hawaiians are struggling to stay on the islands amid skyrocketing housing prices, while others have been forced to move away.
Meanwhile, after the fires, Filipino families faced particularly stark barriers to getting information about financial support, government assistance, housing, and DNA testing. Filipinos make up about 25% of Hawaii’s population and 40% of its workers in the tourism industry. They also make up 46% of undocumented residents in Hawaii—more than any other group. Some encountered language barriers, since they primarily spoke Tagalog or Ilocano. Some worried that people would try to take over their burned land and develop it for themselves. For many, being asked for DNA samples only added to the confusion and suspicion.
Selden says he hears the overall concerns about DNA testing: “If you ask people about DNA in general, they think of Brave New World and [fear] the information is going to be used to somehow harm or control people.” But just like regular DNA analysis, he explains, rapid DNA analysis “has no information on the person’s appearance, their ethnicity, their health, their behavior either in the past, present, or future.” He describes it as a more accurate fingerprint.
Gin tried to help the Lahaina family members understand that their DNA “isn’t going to go anywhere else.” She told them their sample would ultimately be destroyed, something programmed to occur inside ANDE’s machine. (Selden says the boxes were designed to do this for privacy purposes.) But sometimes, Gin realizes, these promises are not enough.
“You still have a large population of people that, in my experience, don’t want to give up their DNA to a government entity,” she says. “They just don’t.”
Gin understands that family members are often nervous to give their DNA samples. She promises the process of rapid DNA analysis respects their privacy, but she knows sometimes promises aren’t enough.
BRYAN TARNOWSKI
The immediate aftermath of a disaster, when people are suffering from shock, PTSD, and displacement, is the worst possible moment to try to educate them about DNA tests and explain the technology and privacy policies. “A lot of them don’t have anything,” Gin says. “They’re just wondering where they’re going to lay their heads down, and how they’re going to get food and shelter and transportation.”
Unfortunately, Lahaina’s survivors won’t be the last people in this position. Particularly given the world’s current climate trajectory, the risk of deadly events in just about every neighborhood and community will rise. And figuring out who survived and who didn’t will be increasingly difficult. Mann recalls his work on the Indian Ocean tsunami, when over 227,000 people died. “The bodies would float off, and they ended up 100 miles away,” he says. Investigators were at times left with remains that had been consumed by sea creatures or degraded by water and weather. He remembers how they struggled to determine: “Who is the person?”
Mann has spent his own career identifying people including “missing soldiers, sailors, airmen, Marines, from all past wars,” as well as people who have died recently. That closure is meaningful for family members, some of them decades, or even lifetimes, removed.
In the end, distrust and conspiracy theories did in fact hinder DNA-identification efforts on Maui, according to a police department report.
33 days
By the time Raven went to a family resource center to submit a swab, some four weeks had gone by. He remembers the quick rub inside his cheek.
Some of his family had already offered their own samples before Raven provided his. For them, waiting wasn’t an issue of mistrusting the testing as much as experiencing confusion and chaos in the weeks after the fire. They believed Uncle Raffy was still alive, and they still held hope of finding him. Offering DNA was a final step in their search.
“I did it for my mom,” Raven says. She still wanted to believe he was alive, but Raven says: “I just had this feeling.” His father, he told himself, must be gone.
Just a day after he gave his sample—on September 11, more than a month after the fire—he was at the temporary house in Kihei when he got the call: “It was,” Raven says, “an automatic match.”
Raven gave a cheek swab about a month after the disappearance of his father. It didn’t take long for him to get a phone call: “It was an automatic match.”
WINNI WINTERMEYER
The investigators let the family know the address where the remains of Rafael Sr. had been found, several blocks away from their home. They put it into Google Maps and realized it was where some family friends lived. The mother and son of that family had been listed as missing too. Rafael Sr., it seemed, had been with or near them in the end.
By October, investigators in Lahaina had obtained and analyzed 215 DNA samples from family members of the missing. By December, DNA analysis had confirmed the identities of 63 of the most recent count of 101 victims. Seventeen more had been identified by fingerprint, 14 via dental records, and two through medical devices, along with three who died in the hospital. While some of the most damaged remains would still be undergoing DNA testing months after the fires, it’s a drastic improvement over the identification processes for 9/11 victims, for instance—today, over 20 years later, some are still being identified by DNA.
Raven remembers how much his father loved karaoke. His favorite song was “My Way,” by Frank Sinatra.
COURTESY OF RAVEN IMPERIAL
Rafael Sr. was born on October 22, 1959, in Naga City, the Philippines. The family held his funeral on his birthday last year. His relatives flew in from Michigan, the Philippines, and California.
Raven says in those weeks of waiting—after all the false tips, the searches, the prayers, the glimmers of hope—deep down the family had already known he was gone. But for Evelyn, Raphael Jr., and the rest of their family, DNA tests were necessary—and, ultimately, a relief, Raven says. “They just needed that closure.”
Erika Hayasaki is an independent journalist based in Southern California.
This article is from The Spark, MIT Technology Review’s weekly climate newsletter. To receive it in your inbox every Wednesday, sign up here.
I’m ready for summer, but if this year is anything like last year, it’s going to be a doozy. In fact, the summer of 2023 in the Northern Hemisphere was the hottest in over 2,000 years, according to a new study released this week.
If you’ve been following the headlines, you probably already know that last year was a hot one. But I was gobsmacked by this paper’s title when it came across my desk. The warmest in 2,000 years—how do we even know that?
There weren’t exactly thermometers around in the year 1, so scientists have to get creative when it comes to comparing our climate today with that of centuries, or even millennia, ago. Here’s how our world stacks up against the climate of the past, how we know, and why it matters for our future.
Today, there are thousands and thousands of weather stations around the globe, tracking the temperature from Death Valley to Mount Everest. So there’s plenty of data to show that 2023 was, in a word, a scorcher.
But scientists decided to look even further back into the past for a year that could compare to our current temperatures. To do so, they turned to trees, which can act as low-tech weather stations.
The concentric rings inside a tree are evidence of the plant’s yearly growth cycles. Lighter colors correspond to quick growth over the spring and summer, while the darker rings correspond to the fall and winter. Count the pairs of light and dark rings, and you can tell how many years a tree has lived.
Trees tend to grow faster during warm, wet years and slower during colder ones. So scientists can not only count the rings but measure their thickness, and use that as a gauge for how warm any particular year was. They also look at factors like density and track different chemical signatures found inside the wood. You don’t even need to cut down a tree to get its help with climatic studies—you can just drill out a small cylinder from the tree’s center, called a core, and study the patterns.
The oldest living trees allow us to peek a few centuries into the past. Beyond that, it’s a matter of cross-referencing the patterns on dead trees with living ones, extending the record back in time like putting a puzzle together.
It’s taken several decades of work and hundreds of scientists to develop the records that researchers used for this new paper, said Max Torbenson, one of the authors of the study, on a press call. There are over 10,000 trees from nine regions across the Northern Hemisphere represented, allowing the researchers to draw conclusions about individual years over the past two millennia. The year 246 CE once held the crown for the warmest summer in the Northern Hemisphere in the last 2,000 years. But 25 of the last 28 years have beat that record, Torbenson says, and 2023’s summer tops them all.
These conclusions are limited to the Northern Hemisphere, since there are only a few tree ring records from the Southern Hemisphere, says Jan Esper, lead author of the new study. And using tree rings doesn’t work very well for the tropics because seasons look different there, he adds. Since there’s no winter, there’s usually not as reliable an alternating pattern in tropical tree rings, though some trees do have annual rings that track the wet and dry periods of the year.
Paleoclimatologists, who study ancient climates, can use other methods to get a general idea of what the climate looked like even earlier—tens of thousands to millions of years ago.
The biggest difference between the new study using tree rings and methods of looking back further into the past is the precision. Scientists can, with reasonable certainty, use tree rings to draw conclusions about individual years in the Northern Hemisphere (536 CE was the coldest, for instance, likely because of volcanic activity). Any information from further back than the past couple of thousand years will be more of a general trend than a specific data point representing a single year. But those records can still be very useful.
The oldest glaciers on the planet are at least a million years old, and scientists can drill down into the ice for samples. By examining the ratio of gases like oxygen, carbon dioxide, and nitrogen inside these ice cores, researchers can figure out the temperature of the time corresponding to the layers in the glacier. The oldest continuous ice-core record, which was collected in Antarctica, goes back about 800,000 years.
Researchers can use fossils to look even further back into Earth’s temperature record. For one 2020 study, researchers drilled into the seabed and looked at the sediment and tiny preserved shells of ancient organisms. From the chemical signatures in those samples, they found that the temperatures we might be on track to record may be hotter than anything the planet has experienced on a global scale in tens of millions of years.
It’s a bit sobering to know that we’re changing the planet in such a dramatic way.
The good news is, we know what we need to do to turn things around: cut emissions of planet-warming gases like carbon dioxide and methane. The longer we wait, the more expensive and difficult it will be to stop warming and reverse it, as Esper said on the press call: “We should do as much as possible, as soon as possible.”
Now read the rest of The Spark
Related reading
Last year broke all sorts of climate records, from emissions to ocean temperatures. For more on the data, check out this story from December.
Readers chose thermal batteries as the 11th Breakthrough Technology of 2024. If you want to hear more about what thermal batteries are, how they work, and why this all matters, join us for the latest in our Roundtables series of online events, where I’ll be getting into the nitty-gritty details and answering some audience questions.
This event is exclusively for subscribers, so subscribe if you haven’t already, and then register here to join us tomorrow, May 16, at noon Eastern time. Hope to see you there!
Keeping up with climate
Scientists just recorded the largest ever annual leap in the amount of carbon dioxide in the atmosphere. The concentration of the planet-warming gas in March 2024 was 4.7 parts per million higher than it was a year before. (The Guardian)
Tesla has reportedly begun rehiring some of the workers who were laid off from its charging team in recent weeks. (Bloomberg)
→ To catch up on what’s going on at Tesla, and what it means for the future of EV charging and climate tech more broadly, check out the newsletter from last week if you missed it. (MIT Technology Review)
A new rule could spur thousands of miles of new power lines, making it easier to add renewables to the grid in the US. The Federal Energy Regulatory Commission will require grid operators to plan 20 years ahead, considering things like the speed of wind and solar installations. (New York Times)
Where does carbon dioxide go after it’s been vacuumed out of the atmosphere? Here are 10 options. (Latitude Media)
Ocean temperatures have been extremely high, shattering records over the past year. All that heat could help fuel a particularly busy upcoming hurricane season. (E&E News)
New tariffs in the US will tack on additional costs to a wide range of Chinese imports, including batteries and solar cells. The tariff on EVs will take a particularly drastic jump, going from 27.5% to 102.5%. (Associated Press)
A reporter took a trip to the Beijing Auto Show and drove dozens of EVs. His conclusion? Chinese EVs are advancing much faster than Western automakers can keep up with. (InsideEVs)
Harnessing solar power via satellites in space and beaming it down to Earth is a tempting dream. But the reality, as you might expect, is probably not so rosy. (IEEE Spectrum)
Recent highly publicized scandals have gotten the physics community worried about its reputation—and its future. Over the last five years, several claims of major breakthroughs in quantum computing and superconducting research, published in prestigious journals, have disintegrated as other researchers found they could not reproduce the blockbuster results.
Last week, around 50 physicists, scientific journal editors, and emissaries from the National Science Foundation gathered at the University of Pittsburgh to discuss the best way forward.“To be honest, we’ve let it go a little too long,” says physicist Sergey Frolov of the University of Pittsburgh, one of the conference organizers.
The attendees gathered in the wake of retractions from two prominent research teams. One team, led by physicist Ranga Dias of the University of Rochester, claimed that it had invented the world’s first room temperature superconductor in a 2023 paper in Nature. After independent researchers reviewed the work, a subsequent investigation from Dias’s university found that he had fabricated and falsified his data. Nature retracted the paper in November 2023. Last year, Physical Review Lettersretracted a 2021 publication on unusual properties in manganese sulfide that Dias co-authored.
The other high-profile research team consisted of researchers affiliated with Microsoft working to build a quantum computer. In 2021, Nature retracted the team’s 2018 paper that claimed the creation of a pattern of electrons known as a Majorana particle, a long-sought breakthrough in quantum computing. Independent investigations of that research found that the researchers had cherry-picked their data, thus invalidating their findings. Another less-publicized research team pursuing Majorana particles fell to a similar fate, with Science retracting a 2017 article claiming indirect evidence of the particles in 2022.
In today’s scientific enterprise, scientists perform research and submit the work to editors. The editors assign anonymous referees to review the work, and if the paper passes review, the work becomes part of the accepted scientific record. When researchers do publish bad results, it’s not clear who should be held accountable—the referees who approved the work for publication, the journal editors who published it, or the researchers themselves. “Right now everyone’s kind of throwing the hot potato around,” says materials scientist Rachel Kurchin of Carnegie Mellon University, who attended the Pittsburgh meeting.
Much of the three-day meeting, named the International Conference on Reproducibility in Condensed Matter Physics (a field that encompasses research into various states of matter and why they exhibit certain properties), focused on the basic scientific principle that an experiment and its analysis must yield the same results when repeated. “If you think of research as a product that is paid for by the taxpayer, then reproducibility is the quality assurance department,” Frolov told MIT Technology Review. Reproducibility offers scientists a check on their work, and without it, researchers might waste time and money on fruitless projects based on unreliable prior results, he says.
In addition to presentations and panel discussions, there was a workshop during which participants split into groups and drafted ideas for guidelines that researchers, journals, and funding agencies could follow to prioritize reproducibility in science. The tone of the proceedings stayed civil and even lighthearted at times. Physicist Vincent Mourik of Forschungszentrum Jülich, a German research institution, showed a photo of a toddler eating spaghetti to illustrate his experience investigating another team’s now-retracted experiment. Occasionally the discussion almost sounded like a couples counseling session, with NSF program director Tomasz Durakiewicz asking a panel of journal editors and a researcher to reflect on their “intimate bond based on trust.”
But researchers did not shy from directly criticizing Nature, Science, and the Physical Review family of journals, all of which sent editors to attend the conference. During a panel, physicist Henry Legg of the University of Basel in Switzerland called out the journal Physical Review B for publishing a paper on a quantum computing device by Microsoft researchers that, for intellectual-property reasons, omitted information required for reproducibility. “It does seem like a step backwards,” Legg said. (Sitting in the audience, Physical Review B editor Victor Vakaryuk said that the paper’s authors had agreed to release “the remaining device parameters” by the end of the year.)
Journals also tend to “focus on story,” said Legg, which can lead editors to be biased toward experimental results that match theoretical predictions. Jessica Thomas, the executive editor of the American Physical Society, which publishes the Physical Review journals, pushed back on Legg’s assertion. “I don’t think that when editors read papers, they’re thinking about a press release or [telling] an amazing story,” Thomas told MIT Technology Review. “I think they’re looking for really good science.” Describing science through narrative is a necessary part of communication, she says. “We feel a responsibility that science serves humanity, and if humanity can’t understand what’s in our journals, then we have a problem.”
Frolov, whose independent review with Mourik of the Microsoft work spurred its retraction, said he and Mourik have had to repeatedly e-mail the Microsoft researchers and other involved parties to insist on data. “You have to learn how to be an asshole,” he told MIT Technology Review. “It shouldn’t be this hard.”
At the meeting, editors pointed out that mistakes, misconduct, and retractions have always been a part of science in practice. “I don’t think that things are worse now than they have been in the past,” says Karl Ziemelis, an editor at Nature.
Ziemelis also emphasized that “retractions are not always bad.” While some retractions occur because of research misconduct, “some retractions are of a much more innocent variety—the authors having made or being informed of an honest mistake, and upon reflection, feel they can no longer stand behind the claims of the paper,” he said while speaking on a panel. Indeed, physicist James Hamlin of the University of Florida, one of the presenters and an independent reviewer of Dias’s work, discussed how he had willingly retracted a 2009 experiment published in Physical Review Letters in 2021 after another researcher’s skepticism prompted him to reanalyze the data.
What’s new is that “the ease of sharing data has enabled scrutiny to a larger extent than existed before,” says Jelena Stajic, an editor at Science. Journals and researchers need a “more standardized approach to how papers should be written and what needs to be shared in peer review and publication,” she says.
Focusing on the scandals “can be distracting” from systemic problems in reproducibility, says attendee Frank Marsiglio, a physicist at the University of Alberta in Canada. Researchers aren’t required to make unprocessed data readily available for outside scrutiny. When Marsiglio has revisited his own published work from a few years ago, sometimes he’s had trouble recalling how his former self drew those conclusions because he didn’t leave enough documentation. “How is somebody who didn’t write the paper going to be able to understand it?” he says.
Problems can arise when researchers get too excited about their own ideas. “What gets the most attention are cases of fraud or data manipulation, like someone copying and pasting data or editing it by hand,” says conference organizer Brian Skinner, a physicist at Ohio State University. “But I think the much more subtle issue is there are cool ideas that the community wants to confirm, and then we find ways to confirm those things.”
But some researchers may publish bad data for a more straightforward reason. The academic culture, popularly described as “publish or perish,” creates an intense pressure on researchers to deliver results. “It’s not a mystery or pathology why somebody who’s under pressure in their work might misstate things to their supervisor,” said Eugenie Reich, a lawyer who represents scientific whistleblowers, during her talk.
Notably, the conference lacked perspectives from researchers based outside the US, Canada, and Europe, and from researchers at companies. In recent years, academics have flocked to companies such as Google, Microsoft, and smaller startups to do quantum computing research, and they have published their work in Nature, Science, and the Physical Review journals. Frolov says he reached out to researchers from a couple of companies, but “that didn’t work out just because of timing,” he says. He aims to include researchers from that arena in future conversations.
After discussing the problems in the field, conference participants proposed feasible solutions for sharing data to improve reproducibility. They discussed how to persuade the community to view data sharing positively, rather than seeing the demand for it as a sign of distrust. They also brought up the practical challenges of asking graduate students to do even more work by preparing their data for outside scrutiny when it may already take them over five years to complete their degree. Meeting participants aim to publicly release a paper with their suggestions. “I think trust in science will ultimately go up if we establish a robust culture of shareable, reproducible, replicable results,” says Frolov.
Sophia Chen is a science writer based in Columbus, Ohio. She has written for the society that publishes the Physical Review journals, and for the news section of Nature.
This week, Google and OpenAI both announced they’ve built supercharged AI assistants: tools that can converse with you in real time and recover when you interrupt them, analyze your surroundings via live video, and translate conversations on the fly.
OpenAI struck first on Monday, when it debuted its new flagship model GPT-4o. The live demonstration showed it reading bedtime stories and helping to solve math problems, all in a voice that sounded eerily like Joaquin Phoenix’s AI girlfriend in the movie Her (a trait not lost on CEO Sam Altman).
On Tuesday, Google announced its own new tools, including a conversational assistant called Gemini Live, which can do many of the same things. It also revealed that it’s building a sort of “do-everything” AI agent, which is currently in development but will not be released until later this year.
Soon you’ll be able to explore for yourself to gauge whether you’ll turn to these tools in your daily routine as much as their makers hope, or whether they’re more like a sci-fi party trick that eventually loses its charm. Here’s what you should know about how to access these new tools, what you might use them for, and how much it will cost.
OpenAI’s GPT-4o
What it’s capable of: The model can talk with you in real time, with a response delay of about 320 milliseconds, which OpenAI says is on par with natural human conversation. You can ask the model to interpret anything you point your smartphone camera at, and it can provide assistance with tasks like coding or translating text. It can also summarize information, and generate images, fonts, and 3D renderings.
How to access it: OpenAI says it will start rolling out GPT-4o’s text and vision features in the web interface as well as the GPT app, but has not set a date. The company says it will add the voice functions in the coming weeks, although it’s yet to set an exact date for this either. Developers can access the text and vision features in the API now, but voice mode will launch only to a “small group” of developers initially.
How much it costs: Use of GPT-4o will be free, but OpenAI will set caps on how much you can use the model before you need to upgrade to a paid plan. Those who join one of OpenAI’s paid plans, which start at $20 per month, will have five times more capacity on GPT-4o.
Google’s Gemini Live
What is Gemini Live? This is the Google product most comparable to GPT-4o—a version of the company’s AI model that you can speak with in real time. Google says that you’ll also be able to use the tool to communicate via live video “later this year.” The company promises it will be a useful conversational assistant for things like preparing for a job interview or rehearsing a speech.
How to access it: Gemini Live launches in “the coming months” via Google’s premium AI plan, Gemini Advanced.
How much it costs: Gemini Advanced offers a two-month free trial period and costs $20 per month thereafter.
But wait, what’s Project Astra? Astra is a project to build a do-everything AI agent, which was demoed at Google’s I/O conference but will not be released until later this year.
People will be able to use Astra through their smartphones and possibly desktop computers, but the company is exploring other options too, such as embedding it into smart glasses or other devices, Oriol Vinyals, vice president of research at Google DeepMind, told MIT Technology Review.
Which is better?
It’s hard to tell without having hands on the full versions of these models ourselves. Google showed off Project Astra through a polished video, whereas OpenAI opted to debut GPT-4o via a seemingly more authentic live demonstration, but in both cases, the models were asked to do things the designers likely already practiced. The real test will come when they’re debuted to millions of users with unique demands.
That said, if you compare OpenAI’s published videoswith Google’s, the two leading tools look very similar, at least in their ease of use. To generalize, GPT-4o seems to be slightly ahead on audio, demonstrating realistic voices, conversational flow, and even singing, whereas Project Astra shows off more advanced visual capabilities, like being able to “remember” where you left your glasses. OpenAI’s decision to roll out the new features more quickly might mean its product will get more use at first than Google’s, which won’t be fully available until later this year. It’s too soon to tell which model “hallucinates” false information less often or creates more useful responses.
Are they safe?
Both OpenAI and Google say their models are well tested: OpenAI says GPT-4o was evaluated by more than 70 experts in fields like misinformation and social psychology, and Google has said that Gemini “has the most comprehensive safety evaluations of any Google AI model to date, including for bias and toxicity.”
But these companies are building a future where AI models search, vet, and evaluate the world’s information for us to serve up a concise answer to our questions. Even more so than with simpler chatbots, it’s wise to remain skeptical about what they tell you.
When a commercial ship travels from the port of Ras Tanura in Saudi Arabia to Tokyo Bay, it’s not only carrying cargo; it’s also transporting millions of data points across a wide array of partners and complex technology systems.
Consider, for example, Maersk. The global shipping container and logistics company has more than 100,000 employees, offices in 120 countries, and operates about 800 container ships that can each hold 18,000 tractor-trailer containers. From manufacture to delivery, the items within these containers carry hundreds or thousands of data points, highlighting the amount of supply chain data organizations manage on a daily basis.
Until recently, access to the bulk of an organizations’ supply chain data has been limited to specialists, distributed across myriad data systems. Constrained by traditional data warehouse limitations, maintaining the data requires considerable engineering effort; heavy oversight, and substantial financial commitment. Today, a huge amount of data—generated by an increasingly digital supply chain—languishes in data lakes without ever being made available to the business.
A 2023 Boston Consulting Group survey notes that 56% of managers say although investment in modernizing data architectures continues, managing data operating costs remains a major pain point. The consultancy also expects data deluge issues are likely to worsen as the volume of data generated grows at a rate of 21% from 2021 to 2024, to 149 zettabytes globally.
“Data is everywhere,” says Mark Sear, director of AI, data, and integration at Maersk. “Just consider the life of a product and what goes into transporting a computer mouse from China to the United Kingdom. You have to work out how you get it from the factory to the port, the port to the next port, the port to the warehouse, and the warehouse to the consumer. There are vast amounts of data points throughout that journey.”
Sear says organizations that manage to integrate these rich sets of data are poised to reap valuable business benefits. “Every single data point is an opportunity for improvement—to improve profitability, knowledge, our ability to price correctly, our ability to staff correctly, and to satisfy the customer,” he says.
Organizations like Maersk are increasingly turning to a data lakehouse architecture. By combining the cost-effective scale of a data lake with the capability and performance of a data warehouse, a data lakehouse promises to help companies unify disparate supply chain data and provide a larger group of users with access to data, including structured, semi-structured, and unstructured data. Building analytics on top of the lakehouse not only allows this new architectural approach to advance supply chain efficiency with better performance and governance, but it can also support easy and immediate data analysis and help reduce operational costs.
This content was produced by Insights, the custom content arm of MIT Technology Review. It was not written by MIT Technology Review’s editorial staff.
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
Google’s Astra is its first AI-for-everything agent
What’s happening: Google is set to launch a new system called Astra later this year. It promises that it will be the most powerful, advanced type of AI assistant it’s ever launched.
What’s an agent? The current generation of AI assistants, such as ChatGPT, can retrieve information and offer answers, but that is about it. But this year, Google is rebranding its assistants as more advanced “agents,” which it says could show reasoning, planning, and memory skills and are able to take multiple steps to execute tasks.
The big picture: Tech companies are in the middle of a fierce competition over AI supremacy, and AI agents are the latest effort from Big Tech firms to show they are pushing the frontier of development. Read the full story.
—Melissa Heikkilä
Technology is probably changing us for the worse—or so we always think
Do we use technology, or does it use us? Do our gadgets improve our lives or just make us weak, lazy, and dumb? These are old questions—maybe older than you think. You’re probably familiar with the way alarmed grown-ups through the decades have assailed the mind-rotting potential of search engines, video games, television, and radio—but those are just the recent examples.
Here at MIT Technology Review, writers have grappled with the effects, real or imagined, of tech on the human mind for over a century. But while we’ve always greeted new technologies with a mixture of fascination and fear, something interesting always happens. We get used to it. Read the full story.
—Timothy Maher
MIT Technology Review is celebrating our 125th anniversary with an online series that draws lessons for the future from our past coverage of technology. Check out this piece from the series by David Rotman, our editor at large, about how fear AI will take our jobs is nothing new.
Hong Kong is safe from China’s Great Firewall—for now
Last week, the Hong Kong Court of Appeal granted an injunction that permits the city government to go to Western platforms like YouTube and Spotify and demand they remove the protest anthem “Glory to Hong Kong,” because the government claims it has been used for sedition.
Aside from the depressing implications for pro-democracy movements’ decline in Hong Kong, this lawsuit has also been an interesting case study of the local government’s complicated relationship with internet control. Although it’s tightening its grip, it’s still wary of imposing full-blown ‘Great Firewall’ style censorship. Read the full story to find out why.
—Zeyi Yang
This story is from China Report, our weekly newsletter covering tech and power in China. Sign up to receive it in your inbox every Tuesday.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 Ilya Sutskever is leaving OpenAI Where its former chief scientist goes next is anyone’s guess. (NYT $) + It’s highly likely Sutskever’s new project will be focussed on AGI.(WP $) + Read our interview with Sutskever from last October. (MIT Technology Review)
2 The US AI roadmap is here Senators claim it’s the “broadest and deepest” piece of AI legislation to date. (WP $) + What’s next for AI regulation in 2024? (MIT Technology Review)
3 A real estate mogul has made a bid to acquire TikTok Frank McCourt has thrown his hat into the ring to own the company’s US business. (WSJ $) + The depressing truth about TikTok’s impending ban. (MIT Technology Review)
4 Neuralink’s brain implant issues are nothing new Insiders claim that the firm has known about problems with the implant’s wires for years. (Reuters)
5 Wannabe mothers are finding sperm donors on Facebook The industry’s sky-high fees are driving women to the social network. (NY Mag $) + I took an international trip with my frozen eggs to learn about the fertility industry. (MIT Technology Review)
6 We’re getting a better idea of how long you can expect to lose weight on Wegovy But we still don’t know how long people have to keep taking the drug to maintain it. (Ars Technica) + Weight-loss injections have taken over the internet. But what does this mean for people IRL? (MIT Technology Review)
7 What do DNA tests for the masses really achieve? Most customers don’t really need to know if they’re genetically predisposed to hate cilantro or not. (Bloomberg $)
8 How to save rainforests from wildfires Even lush green spaces aren’t safe from flames. (Hakai Magazine) + The quest to build wildfire-resistant homes. (MIT Technology Review)
9 Memestocks are mounting a major comeback It’s like 2021 all over again. (Vox)
10 Mark Zuckerberg’s just turned 40 It looks like his new rapper look is here to stay. (Insider $)
Quote of the day
“His brilliance and vision are well known; his warmth and compassion are less well known but no less important.”
—Sam Altman, OpenAI’s CEO, offers a measured response to the news that Ilya Sutskever is leaving the company in a post on X.
The big story
How to measure all the world’s fresh water
December 2021
The Congo River is the world’s second-largest river system after the Amazon. More than 75 million people depend on it for food and water, as do thousands of species of plants and animals. The massive tropical rainforest sprawled across its middle helps regulate the entire Earth’s climate system, but the amount of water in it is something of a mystery.
Scientists rely on monitoring stations to track the river, but what was once a network of some 400 stations has dwindled to just 15. Measuring water is key to helping people prepare for natural disasters and adapt to climate change—so researchers are increasingly filling data gaps using information gathered from space. Read the full story.
—Maria Gallucci
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or tweet ’em at me.)
+ The Cookie Monster had no right to go this hard! + It’s time to make product design great again. But how, exactly? + The universe is humming all the time, but no one really knows why. + Who here remembers the original Teenage Mutant Ninja Turtleson NES?
This story first appeared in China Report, MIT Technology Review’s newsletter about technology in China. Sign up to receive it in your inbox every Tuesday.
We finally know the result of a legal case I’ve been tracking in Hong Kong for almost a year. Last week, the Hong Kong Court of Appeal granted an injunction that permits the city government to go to Western platforms like YouTube and Spotify and demand they remove the protest anthem “Glory to Hong Kong,” because the government claims it has been used for sedition.
To read more about how this injunction is specifically designed for Western Big Tech platforms, and the impact it’s likely to have on internet freedom, you can read my story here.
Aside from the depressing implications for pro-democracy movements’ decline in Hong Kong, this lawsuit has also been an interesting case study of the local government’s complicated relationship with internet control and censorship.
I was following this case because it’s a perfect example of how censorship can be built brick by brick. Having reported on China for so long, I sometimes take for granted how powerful and all-encompassing its censorship regime is and need to be reminded that the same can’t be said for most other places in the world.
Hong Kong had a free internet in the past. And unlike mainland China, it remains relatively open: almost all Western platforms and services are still available there, and only a few websites have been censored in recent years.
Since Hong Kong was returned to China from the UK in 1997, the Chinese central government has clashed several times with local pro-democracy movements asking for universal elections and less influence from Beijing. As a result, it started cementing tighter and tighter control over Hong Kong, and people have been worrying about whether its Great Firewall will eventually extend there. But actually, neither Beijing nor Hong Kong may want to see that happen. All the recent legal maneuverings are only necessary because the government doesn’t want a full-on ban of Western platforms.
When I visited Hong Kong last November, it was pretty clear that both Beijing and Hong Kong want to take advantage of the free flow of finance and business through the city. That’s why the Hong Kong government was given tacit permission in 2023 to explore government cryptocurrency projects, even though crypto trading and mining are illegal in China. Hong Kong officials have boasted on many occasions about the city’s value proposition: connecting untapped demand in the mainland to the wider crypto world by attracting mainland investors and crypto companies to set up shop in Hong Kong.
But that wouldn’t be possible if Hong Kong closed off its internet. Imagine a “global” crypto industry that couldn’t access Twitter or Discord. Crypto is only one example, but the things that have made Hong Kong successful—the nonstop exchange of cargo, capital, ideas, and people—would cease to function if basic and universal tools like Google or Facebook became unavailable.
That’s why there are these calculated offenses on internet freedom in Hong Kong. It’s about seeking control but also leaving some breathing space; it’s as much about looking tough on the outside as negotiating with platforms down below; it’s about showing its determination to Beijing but also not showing too much aggression to the West.
For example, the experts I’ve talked to don’t expect the government to request that YouTube remove the videos for everyone globally. More likely, they may ask for the content to be geo-blocked just for users in Hong Kong.
“As long as Hong Kong is still useful as a financial hub, I don’t think they would establish the Great Firewall [there],” says Chung Ching Kwong, a senior analyst at the Inter-Parliamentary Alliance on China, an advocacy organization that connects legislators from over 30 countries working on relations with China.
It’s also the reason why the Hong Kong government has recently come out to say that it won’t outright ban platforms like Telegram and Signal, even though it said that it had received comments from the public asking it to do so.
But coming back to the court decision to restrict “Glory to Hong Kong,” even if the government doesn’t end up enforcing a full-blown ban of the song, as opposed to the more targeted injunction it’s imposed now, it may still result in significant harm to internet freedom.
We are still watching the responses roll in after the court decision last Wednesday. The Hong Kong government is anxiously waiting to hear how Google will react. Meanwhile, some videos have already been taken down, though it’s unclear whether they were pulled by the creators or by the platform.
Michael Mo, a former district councilor in Hong Kong who’s now a postgraduate researcher at the University of Leeds in the UK, created a website right after the injunction was first initiated last June to embed all but one of the YouTube videos the government sought to ban.
The domain name, “gloryto.hk,” was the first test of whether the Hong Kong domain registry would have trouble with it, but nothing has happened to it so far. The second test was seeing how soon the videos would be taken down on YouTube, which is now easy to tell by how many “video unavailable” gaps there are on the page. “Those videos were pretty much intact until the Court of Appeal overturned the rulings of the High Court. The first two have gone,” Mo says.
The court case is having a chilling effect. Even entities that are not governed by the Hong Kong court are taking precautions. Some YouTube accounts owned by media based in Taiwan and the US proactively enabled geo-blocking to restrict people in Hong Kong from watching clips of the song they uploaded as soon as the injunction application was filed, Mo says.
Are you optimistic or pessimistic about the future of internet freedom in Hong Kong? Let me know what you think at zeyi@technologyreview.com.
Now read the rest of China Report
Catch up with China
1. The Biden administration plans to raise tariffs on Chinese-made EVs, from 25% to 100%. Since few Chinese cars are currently sold in the US, this is mostly a move to deter future imports of Chinese EVs. But it could slow down the decarbonization timeline in the US. (ABC News)
2. Government officials from the US and China met in Geneva today to discuss how to mitigate the risks of AI. It’s a notable event, given how rare it is for the two sides to find common ground in the highly politicized field of technology. (Reuters $)
3. It will be more expensive soon to ride the bullet trains in China. A 20% to 39% fare increase is causing controversy among Chinese people. (New York Times $)
4. From executive leadership to workplace culture, TikTok has more in common with its Chinese sister app Douyin than the company wants to admit. (Rest of World)
5. China’s most indebted local governments have started claiming troves of data as “intangible assets” on their accounting books. Given the insatiable appetite for AI training data, they may have a point. (South China Morning Post $)
6. A crypto company with Chinese roots purchased a piece of land in Wyoming for crypto mining. Now the Biden administration is blocking the deal for national security reasons. (Associated Press)
Lost in translation
Recently, following an order made by the government, hotels in many major Chinese cities stopped asking guests to submit to facial recognition during check-in.
As hotels around the country retire their facial recognition kiosks en masse, equipment made by major tech companies has flooded online secondhand markets at steep discounts. What was sold for thousands of dollars is now resold for as little as 1% of the original price. Alipay, the Alibaba-affiliated payment app, once invested hundreds of millions of dollars to research and roll out these kiosks. Now it’s one of the companies being hit the hardest by the policy change.
One more thing
I had to double-check that this is not a joke. It turns out that for the past 10 years, the Louvre museum has been giving visitors a Nintendo 3DS—a popular handheld gaming console—as an audio and visual guide.
It feels weird seeing people holding a 3DS up to the Mona Lisa as if they were in their own private Pokémon Go–style gaming world rather than just enjoying the museum. But apparently it doesn’t work very well anyway. Oops.
and it was THE WORST at navigating bc a 3ds can’t tell which direction you’re facing + the floorplan isn’t updated to match ongoing renovations. kept tryna send me into a wall i almost chucked the thing i stg
MIT Technology Review is celebrating our 125th anniversary with an online series that draws lessons for the future from our past coverage of technology.
Do we use technology, or does it use us? Do our gadgets improve our lives or just make us weak, lazy, and dumb? These are old questions—maybe older than you think. You’re probably familiar with the way alarmed grown-ups through the decades have assailed the mind-rotting potential of search engines, video games, television, and radio—but those are just the recent examples.
Or to go back even further: in Plato’s Phaedrus, from around 370 BCE, Socrates suggests that writing could be a detriment to human memory—the argument being, if you’ve written it down, you no longer needed to remember it.
We’ve always greeted new technologies with a mixture of fascination and fear, says Margaret O’Mara, a historian at the University of Washington who focuses on the intersection of technology and American politics. “People think: ‘Wow, this is going to change everything affirmatively, positively,’” she says. “And at the same time: ‘It’s scary—this is going to corrupt us or change us in some negative way.’”
And then something interesting happens: “We get used to it,” she says. “The novelty wears off and the new thing becomes a habit.”
A curious fact
Here at MIT Technology Review, writers have grappled with the effects, real or imagined, of tech on the human mind for nearly a hundred years. In our March 1931 issue, in his essay “Machine-Made Minds,” author John Bakeless wrote that it was time to ask “how far the machine’s control over us is a danger calling for vigorous resistance; and how far it is a good thing, to which we may willingly yield.”
The advances that alarmed him might seem, to us, laughably low-tech: radio transmitters, antennas, or even rotary printing presses.
But Bakeless, who’d published books on Lewis and Clark and other early American explorers, wanted to know not just what the machine age was doing to society but what it was doing to individual people. “It is a curious fact,” he wrote, “that the writers who have dealt with the social, economic, and political effects of the machine have neglected the most important effect of all—its profound influence on the human mind.”
In particular, he was worried about how technology was being used by the media to control what people thought and talked about.
“Consider the mental equipment of the average modern man,” he wrote. “Most of the raw material of his thought enters his mind by way of a machine of some kind … the Twentieth Century journalist can collect, print, and distribute his news with a speed and completeness wholly due to a score or more of intricate machines … For the first time, thanks to machinery, such a thing as a world-wide public opinion is becoming possible.”
Bakeless didn’t see this as an especially positive development. “Machines are so expensive that the machine-made press is necessarily controlled by a few very wealthy men, who with the very best intentions in the world are still subject to human limitation and the prejudices of their kind … Today the man or the government that controls two machines—wireless and cable—can control the ideas and passions of a continent.”
Keep away
Fifty years later, the debate had shifted more in the direction of silicon chips. In our October 1980 issue, engineering professor Thomas B. Sheridan, in “Computer Control and Human Alienation,” asked: “How can we ensure that the future computerized society will offer humanity and dignity?” A few years later, in our August/September 1987 issue, writer David Lyon felt he had the answer—we couldn’t, and wouldn’t. In “Hey You! Make Way for My Technology,” he wrote that gadgets like the telephone answering machine and the boom box merely kept other pesky humans at a safe distance: “As machines multiply our capacity to perform useful tasks, they boost our aptitude for thoughtless and self-centered action. Civilized behavior is predicated on the principle of one human being interacting with another, not a human being interacting with a mechanical or electronic extension of another person.”
By this century the subject had been taken up by a pair of celebrities, novelist Jonathan Franzen and Talking Heads lead vocalist David Byrne. In our September/October 2008 issue, Franzen suggested that cell phones had turned us into performance artists.
In “I Just Called to Say I Love You,” he wrote: “When I’m buying those socks at the Gap and the mom in line behind me shouts ‘I love you!’ into her little phone, I am powerless not to feel that something is being performed; overperformed; publicly performed; defiantly inflicted. Yes, a lot of domestic things get shouted in public which really aren’t intended for public consumption; yes, people get carried away. But the phrase ‘I love you’ is too important and loaded, and its use as a sign-off too self-conscious, for me to believe I’m being made to hear it accidentally.”
In “Eliminating the Human,” from our September/October 2017 issue, Byrne observed that advances in the digital economy served largely to free us from dealing with other people. You could now “keep in touch” with friends without ever seeing them; buy books without interacting with a store clerk; take an online course without ever meeting the teacher or having any awareness of the other students.
“For us as a society, less contact and interaction—real interaction—would seem to lead to less tolerance and understanding of difference, as well as more envy and antagonism,” Byrne wrote. “As has been in evidence recently, social media actually increases divisions by amplifying echo effects and allowing us to live in cognitive bubbles … When interaction becomes a strange and unfamiliar thing, then we will have changed who and what we are as a species.”
Modern woes
It hasn’t stopped. Just last year our own Will Douglas Heaven’s feature on ChatGPT debunked the idea that the AI revolution will destroy children’s ability to develop critical-thinking skills.
As O’Mara puts it: “Do all of the fears of these moral panics come to pass? No. Does change come to pass? Yes.” The way we come to grips with new technologies hasn’t fundamentally changed, she says, but what has changed is—there’s more of it to deal with. “It’s more of the same,” she says. “But it’s more. Digital technologies have allowed things to scale up into a runaway train of sorts that the 19th century never had to contend with.”
Maybe the problem isn’t technology at all, maybe it’s us. Based on what you might read in 19th-century novels, people haven’t changed much since the early days of the industrial age. In any Dostoyevsky novel you can find people who yearn to be seen as different or special, who take affront at any threat to their carefully curated public persona, who feel depressed and misunderstood and isolated, who are susceptible to mob mentality.
“The biology of the human brain hasn’t changed in the last 250 years,” O’Mara says. “Same neurons, still the same arrangement. But it’s been presented with all these new inputs … I feel like I live with information overload all the time. I think we all observe it in our own lives, how our attention spans just go sideways. But that doesn’t mean my brain has changed at all. We’re just getting used to consuming information in a different way.”
And if you find technology to be intrusive and unavoidable now, it might be useful to note that Bakeless felt no differently in 1931. Even then, long before anyone had heard of smartphone or the internet, he felt that technology had become so intrinsic to daily life that it was like a tyrant: “Even as a despot, the machine is benevolent; and it is after all our stupidity that permits inanimate iron to be a despot at all.”
If we are to ever create the ideal human society, he concluded—one with sufficient time for music, art, philosophy, scientific inquiry (“the gorgeous playthings of the mind,” as he put it)—it was unlikely we’d get it done without the aid of machines. It was too late, we’d already grown too accustomed to the new toys. We just needed to find a way to make sure that the machines served us instead of the other way around. “If we are to build a great civilization in America, if we are to win leisure for cultivating the choice things of mind and spirit, we must put the machine in its place,” he wrote.
Okay, but—how, exactly? Ninety-three years later and we’re still trying to figure that part out.
Google is set to introduce a new system called Astra later this year and promises that it will be the most powerful, advanced type of AI assistant it’s ever launched.
The current generation of AI assistants, such as ChatGPT, can retrieve information and offer answers, but that is about it. But this year, Google is rebranding its assistants as more advanced “agents,” which it says could show reasoning, planning, and memory skills and are able to take multiple steps to execute tasks.
People will be able to use Astra through their smartphones and possibly desktop computers, but the company is exploring other options too, such as embedding it into smart glasses or other devices, Oriol Vinyals, vice president of research at Google DeepMind, told MIT Technology Review.
“We are in very early days [of AI agent development],” Google CEO Sundar Pichai said on a call ahead of Google’s I/O conference today.
“We’ve always wanted to build a universal agent that will be useful in everyday life,” said Demis Hassabis, the CEO and cofounder of Google DeepMind. “Imagine agents that can see and hear what we do, better understand the context we’re in, and respond quickly in conversation, making the pace and quality of interaction feel much more natural.” That, he says, is what Astra will be.
Google’s announcement comes a day after competitor OpenAI unveiled its own supercharged AI assistant, GPT-4o. Google DeepMind’s Astra responds to audio and video inputs, much in the same way as GPT-4o (albeit it less flirtatiously).
In a press demo, a user pointed a smartphone camera and smart glasses at things and asked Astra to explain what they were. When the person pointed the device out the window and asked “What neighborhood do you think I’m in?” the AI system was able to identify King’s Cross, London, site of Google DeepMind’s headquarters. It was also able to say that the person’s glasses were on a desk, having recorded them earlier in the interaction.
The demo showcases Google DeepMind’s vision of multimodal AI (which can handle multiple types of input—voice, video, text, and so on) working in real time, Vinyals says.
“We are very excited about, in the future, to be able to really just get closer to the user, assist the user with anything that they want,” he says. Google recently upgraded its artificial-intelligence model Gemini to process even larger amounts of data, an upgrade which helps it handle bigger documents and videos, and have longer conversations.
Tech companies are in the middle of a fierce competition over AI supremacy, and AI agents are the latest effort from Big Tech firms to show they are pushing the frontier of development. Agents also play into a narrative by many tech companies, including OpenAI and Google DeepMind, that aim to build artificial general intelligence, a highly hypothetical idea of superintelligent AI systems.
“Eventually, you’ll have this one agent that really knows you well, can do lots of things for you, and can work across multiple tasks and domains,” says Chirag Shah, a professor at the University of Washington who specializes in online search.
This vision is still aspirational. But today’s announcement should be seen as Google’s attempt to keep up with competitors. And by rushing these products out, Google can collect even more data from its over a billion users on how they are using their models and what works, Shah says.
Google is unveiling many more new AI capabilities beyond agents today. It’s going to integrate AI more deeply into Search through a new feature called AI overviews, which gather information from the internet and package them into short summaries in response to search queries. The feature, which launches today, will initially be available only in the US, with more countries to gain access later.
This will help speed up the search process and get users more specific answers to more complex, niche questions, says Felix Simon, a research fellow in AI and digital news at the Reuters Institute for Journalism. “I think that’s where Search has always struggled,” he says.
Another new feature of Google’s AI Search offering is better planning. People will soon be able to ask Search to make meal and travel suggestions, for example, much like asking a travel agent to suggest restaurants and hotels. Gemini will be able to help them plan what they need to do or buy to cook recipes, and they will also be able to have conversations with the AI system, asking it to do anything from relatively mundane tasks, such as informing them about the weather forecast, to highly complex ones like helping them prepare for a job interview or an important speech.
People will also be able to interrupt Gemini midsentence and ask clarifying questions, much as in a real conversation.
In another move to one-up competitor OpenAI, Google also unveiled Veo, a new video-generating AI system. Veo is able to generate short videos and allows users more control over cinematic styles by understanding prompts like “time lapse” or “aerial shots of a landscape.”
Google has a significant advantage when it comes to training generative video models, because it owns YouTube. It’s already announced collaborations with artists such as Donald Glover and Wycleaf Jean, who are using its technology to produce their work.
Earlier this year, OpenA’s CTO, Mira Murati, fumbled when asked about whether the company’s model was trained on YouTube data. Douglas Eck, senior research director at Google DeepMind, was also vague about the training data used to create Veo when asked about by MIT Technology Review, but he said that it “may be trained on some YouTube content in accordance with our agreements with YouTube creators.”
On one hand, Google is presenting its generative AI as a tool artists can use to make stuff, but the tools likely get their ability to create that stuff by using material from existing artists, says Shah. AI companies such as Google and OpenAI have faced a slew of lawsuits by writers and artists claiming that their intellectual property has been used without consent or compensation.
“For artists it’s a double-edged sword,” says Shah.
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
OpenAI’s new GPT-4o lets people interact using voice or video in the same model
The news: OpenAI just debuted GPT-4o, a new kind of AI model that you can communicate with in real time via live voice conversation, video streams from your phone, and text. The model is rolling out over the next few weeks and will be free for all users through both the GPT app and the web interface, according to the company.
How does it differ to GPT-4? GPT-4 also gives users multiple ways to interact with OpenAI’s AI offerings. But it siloed them in separate models, leading to longer response times and presumably higher computing costs. GPT-4o has now merged those capabilities into a single model to deliver faster responses and smoother transitions between tasks.
The big picture: The result, the company’s demonstration suggests, is a conversational assistant much in the vein of Siri or Alexa—but capable of fielding much more complex prompts. Read the full story.
—James O’Donnell
What to expect at Google I/O
Google is holding its I/O conference today, May 14, and we expect them to announce a whole new slew of AI features, further embedding it into everything it does.
There has been a lot of speculation that it will upgrade its crown jewel, Search, with generative AI features that could, for example, go behind a paywall. Google, despite having 90% of the online search market, is in a defensive position this year. It’s racing to catch up with its rivals Microsoft and OpenAI, while upstarts such as Perplexity AI have launched their own versions of AI-powered search to rave reviews.
While the company is tight-lipped about its announcements, we can make educated guesses. Read the full story.
—Melissa Heikkilä
This story is from The Algorithm, our weekly AI newsletter. Sign up to receive it in your inbox every Monday.
Get ready for EmTech Digital
If you want to learn more about how Google plans to develop and deploy AI, come and hear from its vice president of AI, Jay Yagnik, at our flagship AI conference, EmTech Digital. We’ll hear from OpenAI about its video generation model Sora too, and Nick Clegg, Meta’s president of global affairs, will also join MIT Technology Review’s executive editor Amy Nordrum for an exclusive interview on stage.
It’ll be held at the MIT campus and streamed live online next week on May 22-23. Readers of The Download get 30% off tickets with the code DOWNLOADD24—register here for more information. See you there!
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 US senators are preparing to unveil their ‘AI roadmap’ The guidelines, which aren’t legislation, will cost billions of dollars to implement. (WP $) + What’s next for AI regulation. (MIT Technology Review)
2 It’s going to get much more expensive to import tech from China The Biden administration has hiked tariffs on batteries, EVs and semiconductors. (FT $) + Three takeaways about the state of Chinese tech in the US. (MIT Technology Review)
3 The NYC mayor wants to equip the subway with gun-detection tech Even though the firm maintains its detectors aren’t designed for that environment. (Wired $) + The maker’s relationship with Disney appears to have been a key factor in the decision. (The Verge) + Can AI keep guns out of schools? (MIT Technology Review)
4 A Chinese crypto miner has been forced to abandon its facility in Wyoming The US said it was too close to an Air Force base and a data center doing work for the Pentagon. (Bloomberg $) + Microsoft first flagged the mine to authorities last year. (NYT $) + How Bitcoin mining devastated this New York town. (MIT Technology Review)
5 App Stores are big business And governments want to rein them in. (Economist $)
6 How social media ads attract networks of predators Audience tools highlight how platforms’ algorithms direct them to pictures of children. (NYT $)
7 Enterprising Amazon workers are using bots to nab time off slots Employees are using automated scripts to gain an edge over their colleagues. (404 Media)
8 Dating app Bumble is ditching its ads criticizing celibacy Critics say the billboards undermined daters’ freedom of choice. (WSJ $) + The platform is in a state of flux right now. (NY Mag $)
9 Buying digital movies is a risky business What happens if the platform you bought them on shuts down? (The Guardian)
10 The New York-Dublin video portal has been temporarily shut down Who could have predicted that people would behave inappropriately? (BBC) + There have been some heartwarming interactions too, though. (The Guardian)
Quote of the day
“Rewatched Her last weekend and it felt a lot like rewatching Contagion in Feb 2020.”
—Noam Brown, an OpenAI researcher, reflects on X about the vast changes the company’s new companion AI model GPT-4o could usher in.
The big story
I took an international trip with my frozen eggs to learn about the fertility industry
September 2022
—Anna Louie Sussman
Like me, my eggs were flying economy class. They were ensconced in a cryogenic storage flask packed into a metal suitcase next to Paolo, the courier overseeing their passage from a fertility clinic in Bologna, Italy, to the clinic in Madrid, Spain, where I would be undergoing in vitro fertilization.
The shipping of gametes and embryos around the world is a growing part of a booming global fertility sector. As people have children later in life, the need for fertility treatment increases each year.
After paying for storage costs for years, at 40 I was ready to try to get pregnant. And transporting the Bolognese batch served to literally put all my eggs in one basket. Read the full story.
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or tweet ’em at me.)+ Bayley the sheepadoodle really does look just like Snoopy. + The secret to better sleep? Setting a consistent wake-up time (and sticking to it.) + Going Nemo-spotting in the Great Barrier Reef sounds pretty amazing. + Here’s exactly what the benefits of eating colorful fruit and veg are, broken down by color.
This story originally appeared in The Algorithm, our weekly newsletter on AI. To get stories like this in your inbox first, sign up here.
In the world of AI, a lot can happen in a year. Last year, at the beginning of Big Tech’s AI wars, Google announced during its annual I/O conference that it was throwing generative AI at everything, integrating it into its suite of products from Docs to email to e-commerce listings and its chatbot Bard. It was an effort to catch up with competitors like Microsoft and OpenAI, which had unveiled snazzy products like coding assistants and ChatGPT, the product that has done more than any other to ignite the current excitement about AI.
Since then, its ChatGPT competitor chatbot Bard (which, you may recall, temporarily wiped $100 billion off Google’s share price when it made a factual error during the demo) has been replaced by the more advanced Gemini. But, for me, the AI revolution hasn’t felt like one. Instead, it’s been a slow slide toward marginal efficiency gains. I see more autocomplete functions in my email and word processing applications, and Google Docs now offers more ready-made templates. They are not groundbreaking features, but they are also reassuringly inoffensive.
Google is holding its I/O conference tomorrow, May 14, and we expect them to announce a whole new slew of AI features, further embedding it into everything it does. The company is tight-lipped about its announcements, but we can make educated guesses. There has been a lot of speculation that it will upgrade its crown jewel, Search, with generative AI features that could, for example, go behind a paywall. Perhaps we will see Google’s version of AI agents, a buzzy word that basically means more capable and useful smart assistants able to do more complex tasks, such as booking flights and hotels much as a travel agent would.
There are some hints about what any new AI-powered search features might look like. Felix Simon, a research fellow at the Reuters Institute for Journalism, has been part of the Google Search Generative Experience trial, which is the company’s way of testing new products on a small selection of real users.
Last month, Simon noticed that his Google searches with links and short snippets from online sources had been replaced by more detailed, neatly packaged AI-generated summaries. He was able to get these results from queries related to nature and health, such as “Do snakes have ears?” Most of the information offered to him was correct, which was a surprise, as AI language models have a tendency to “hallucinate” (which means make stuff up), and they have been criticized for being an unreliable source of information.
To Simon’s surprise, he enjoyed the new feature. “It’s convenient to ask [the AI] to get something presented just for you,” he says.
Simon then started using the new AI-powered Google function to search for news items rather than scientific information.
For most of these queries, such as what happened in the UK or Ukraine yesterday, he was simply offered links to news sources such as the BBC and Al Jazeera. But he did manage to get the search engine to generate an overview of recent news items from Germany, in the form of a bullet-pointed list of news headlines from the day before. The first entry was about an attack on Franziska Giffey, a Berlin politician who was assaulted in a library. The AI summary had the date of the attack wrong. But it was so close to the truth that Simon didn’t think twice about its accuracy.
A quick online search during our call revealed that the rest of the AI-generated news summaries were also littered with inaccuracies. Details were wrong, or the events referred to happened years ago. All the stories were also about terrorism, hate crimes, or violence, with one soccer result thrown in. Omitting headlines on politics, culture, and the economy seems like a weird choice.
People have a tendency to believe computers to be correct even when they are not, and Simon’s experience is an example of the kinds of problems that might arise when AI models hallucinate. The ease of getting results means that people might unknowingly ingest fake news or wrong information. It’s very problematic if even people like Simon, who are trained to fact-check things and know how AI models work, don’t do their due diligence and assume information is correct.
Whatever Google announces at I/O tomorrow, there is immense pressure for it to be something that would justify its massive investment into AI. And after a year of experimenting, there also need to be serious improvements in making its generative AI tools more accurate and reliable.
There are some people in the computer science community who say that hallucinations are an intrinsic part of generative AI that can’t ever be fixed, and that we can never fully trust these systems. But hallucinations will make AI-powered products less appealing to users. And it’s highly unlikely that Google will announce it has fixed this problem at I/O tomorrow.
If you want to learn more about how Google plans to develop and deploy AI, come and hear from its vice president of AI, Jay Yagnik, at our flagship AI conference, EmTech Digital. It’ll be held at the MIT campus and streamed live online next week on May 22-23. I’ll be there, along with AI leaders from companies like OpenAI, AWS, and Nvidia, talking about where AI is going next. Nick Clegg, Meta’s president of global affairs, will also join MIT Technology Review’s executive editor Amy Nordrum for an exclusive interview on stage. See you there!
Readers of The Algorithm get 30% off tickets with the code ALGORITHMD24.
Now read the rest of The Algorithm
Deeper Learning
Deepfakes of your dead loved ones are a booming Chinese business
Once a week, Sun Kai has a video call with his mother. He opens up about work, the pressures he faces as a middle-aged man, and thoughts that he doesn’t even discuss with his wife. His mother will occasionally make a comment, but mostly, she just listens. That’s because Sun’s mother died five years ago. And the person he’s talking to isn’t actually a person, but a digital replica he made of her—a moving image that can conduct basic conversations.
AI resurrection: There are plenty of people like Sun who want to use AI to interact with lost loved ones. The market is particularly strong in China, where at least half a dozen companies are now offering such technologies. In some ways, the avatars are the latest manifestation of a cultural tradition: Chinese people have always taken solace from confiding in the dead. Read more from Zeyi Yang.
Bits and Bytes
Google DeepMind’s new AlphaFold can model a much larger slice of biological life Google DeepMind has released an improved version of its biology prediction tool, AlphaFold, that can predict the structures not only of proteins but of nearly all the elements of biological life. It’s an exciting development that could help accelerate drug discovery and other scientific research. (MIT Technology Review)
The way whales communicate is closer to human language than we realized Researchers used statistical models to analyze whale “codas” and managed to identify a structure to their language that’s similar to features of the complex vocalizations humans use. It’s a small step forward, but it could help unlock a greater understanding of how whales communicate. (MIT Technology Review)
Tech workers should shine a light on the industry’s secretive work with the military Despite what happens in Google’s executive suites, workers themselves can force change. William Fitzgerald, who leaked information about Google’s controversial Project Maven, has shared how he thinks they can do this. (MIT Technology Review)
AI systems are getting better at tricking us A wave of AI systems have “deceived” humans in ways they haven’t been explicitly trained to do, by offering up false explanations for their behavior or concealing the truth from human users and misleading them to achieve a strategic end. This issue highlights how difficult artificial intelligence is to control and the unpredictable ways in which these systems work. (MIT Technology Review)
Why America needs an Apollo program for the age of AI AI is crucial to the future security and prosperity of the US. We need to lay the groundwork now by investing in computational power, argues Eric Schmidt. (MIT Technology Review)
Fooled by AI? These firms sell deepfake detection that’s “REAL 100%” The AI detection business is booming. There is one catch, however. Detecting AI-generated content is notoriously unreliable, and the tech is still in its infancy. That hasn’t stopped some startup founders (many of whom have no experience or background in AI) from trying to sell services they claim can do so. (The Washington Post)
The tech-bro turf war over AI’s most hardcore hacker house A hilarious piece taking an anthropological look at the power struggle between two competing hacker houses in Silicon Valley. The fight is over which house can call itself “AGI House.” (Forbes)
OpenAI just debuted GPT-4o, a new kind of AI model that you can communicate with in real time via live voice conversation, video streams from your phone, and text. The model is rolling out over the next few weeks and will be free for all users through both the GPT app and the web interface, according to the company. Users who subscribe to OpenAI’s paid tiers, which start at $20 per month, will be able to make more requests.
OpenAI CTO Mira Murati led the live demonstration of the new release one day before Google is expected to unveil its own AI advancements at its flagship I/O conference on Tuesday, May 14.
GPT-4 offered similar capabilities, giving users multiple ways to interact with OpenAI’s AI offerings. But it siloed them in separate models, leading to longer response times and presumably higher computing costs. GPT-4o has now merged those capabilities into a single model, which Murati called an “omnimodel.” That means faster responses and smoother transitions between tasks, she said.
The result, the company’s demonstration suggests, is a conversational assistant much in the vein of Siri or Alexa but capable of fielding much more complex prompts.
“We’re looking at the future of interaction between ourselves and the machines,” Murati said of the demo. “We think that GPT-4o is really shifting that paradigm into the future of collaboration, where this interaction becomes much more natural.”
Barret Zoph and Mark Chen, both researchers at OpenAI, walked through a number of applications for the new model. Most impressive was its facility with live conversation. You could interrupt the model during its responses, and it would stop, listen, and adjust course.
OpenAI showed off the ability to change the model’s tone, too. Chen asked the model to read a bedtime story “about robots and love,” quickly jumping in to demand a more dramatic voice. The model got progressively more theatrical until Murati demanded that it pivot quickly to a convincing robot voice (which it excelled at). While there were predictably some short pauses during the conversation while the model reasoned through what to say next, it stood out as a remarkably naturally paced AI conversation.
The model can reason through visual problems in real time as well. Using his phone, Zoph filmed himself writing an algebra equation (3x + 1 = 4) on a sheet of paper, having GPT-4o follow along. He instructed it not to provide answers, but instead to guide him much as a teacher would.
“The first step is to get all the terms with x on one side,” the model said in a friendly tone. “So, what do you think we should do with that plus one?”
Like previous generations of GPT, GPT-4o will store records of users’ interactions with it, meaning the model “has a sense of continuity across all your conversations,” according to Murati. Other new highlights include live translation, the ability to search through your conversations with the model, and the power to look up information in real time.
As is the nature of a live demo, there were hiccups and glitches. GPT-4o’s voice might jump in awkwardly during the conversation. It appeared to comment on one of the presenters’ outfits even though it wasn’t asked to. But it recovered well when the demonstrators told the model it had erred. It seems to be able to respond quickly and helpfully across several mediums that other models have not yet merged as effectively.
Previously, many of OpenAI’s most powerful features, like reasoning through image and video, were behind a paywall. GPT-4o marks the first time they’ll be opened up to the wider public, though it’s not yet clear how many interactions you’ll be able to have with the model before being charged. OpenAI says paying subscribers will “continue to have up to five times the capacity limits of our free users.”
Additional reporting by Will Douglas Heaven.
Correction: This story has been updated to reflect that the Memory feature, which stores past conversations, is not new to GPT-4o but has existed in previous models.
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
What’s next in chips
Thanks to the boom in artificial intelligence, the world of chips is on the cusp of a huge tidal shift. There is heightened demand for chips that can train AI models faster and ping them from devices like smartphones and satellites, enabling us to use these models without disclosing private data. Governments, tech giants, and startups alike are racing to carve out their slices of the growing semiconductor pie.
James O’Donnell, our AI reporter, has dug into the four trends to look for in the year ahead that will define what the chips of the future will look like, who will make them, and which new technologies they’ll unlock. Read on to see what he found out.
Eric Schmidt: Why America needs an Apollo program for the age of AI
—Eric Schmidt was the CEO of Google from 2001 to 2011. He is currently cofounder of philanthropic initiative Schmidt Futures.
The global race for computational power is well underway, fueled by a worldwide boom in artificial intelligence. OpenAI’s Sam Altman is seeking to raise as much as $7 trillion for a chipmaking venture. Tech giants like Microsoft and Amazon are building AI chips of their own.
The need for more computing horsepower to train and use AI models—fueling a quest for everything from cutting-edge chips to giant data sets—isn’t just a current source of geopolitical leverage (as with US curbs on chip exports to China). It is also shaping the way nations will grow and compete in the future, with governments from India to the UK developing national strategies and stockpiling Nvidia graphics processing units.
I believe it’s high time for America to have its own national compute strategy: an Apollo program for the age of AI. Read the full story.
AI systems are getting better at tricking us
The news: A wave of AI systems have “deceived” humans in ways they haven’t been explicitly trained to do, by offering up untrue explanations for their behavior or concealing the truth from human users and misleading them to achieve a strategic end.
Why it matters: Talk of deceiving humans might suggest that these models have intent. They don’t. But AI models will mindlessly find workarounds to obstacles to achieve the goals that have been given to them. Sometimes these workarounds will go against users’ expectations and feel deceitful. Above all, this issue highlights how difficult artificial intelligence is to control, and the unpredictable ways in which these systems work. Read the full story.
—Rhiannon Williams
Why thermal batteries are so hot right now
A whopping 20% of global energy consumption goes to generate heat in industrial processes, most of it using fossil fuels. This often-overlooked climate problem may have a surprising solution in systems called thermal batteries, which can store energy as heat using common materials like bricks, blocks, and sand.
We are holding an exclusive subscribers-only online discussion digging into what thermal batteries are, how they could help cut emissions, and what we can expect next with climate reporter Casey Crownhart and executive editor Amy Nordrum.
We’ll be going live at midday ET on Thursday 16 May. Register here to join us!
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 These companies will happily sell you deepfake detection services The problem is, their capabilities are largely untested. (WP $) + A Hong Kong-based crypto exchange has been accused of deepfaking Elon Musk. (Insider $)+ It’s easier than ever to make seriously convincing deepfakes. (The Guardian) + An AI startup made a hyperrealistic deepfake of me that’s so good it’s scary. (MIT Technology Review)
2 Apple is close to striking a deal with OpenAI To bring ChatGPT to iPhones for the first time. (Bloomberg $)
3 GPS warfare is filtering down into civilian life Once the preserve of the military, unreliable GPS causes havoc for ordinary people. (FT $) + Russian hackers may not be quite as successful as they claim. (Wired $)
4 The first patient to receive a genetically modified pig’s kidney has died But the hospital says his death doesn’t seem to be linked to the transplant. (NYT $) + Synthetic blood platelets could help to address a major shortage. (Wired $) + A woman from New Jersey became the second living recipient just weeks later. (MIT Technology Review)
5 This weekend’s solar storm broke critical farming systems Satellite disruptions temporarily rendered some tractors useless. (404 Media) + The race to fix space-weather forecasting before the next big solar storm hits. (MIT Technology Review)
6 The US can’t get enough of startups Everyone’s a founder now. (Economist $) + Climate tech is back—and this time, it can’t afford to fail. (MIT Technology Review)
7 What AI could learn from game theory AI models aren’t reliable. These tools could help improve that. (Quanta Magazine)
8 The frantic hunt for rare bitcoin is heating up Even rising costs aren’t deterring dedicated hunters. (Wired $)
9 LinkedIn is getting into games Come for the professional networking opportunities, stay for the puzzles. (NY Mag $)
10 Billions of years ago, the Moon had a makeover And we’re only just beginning to understand what may have caused it. (Ars Technica)
Quote of the day
“Human beings are not billiard balls on a table.”
—Sonia Livingstone, a psychologist, explains why it’s so hard to study the impact of technology on young people’s mental health to the Financial Times.
The big story
How greed and corruption blew up South Korea’s nuclear industry
April 2019
In March 2011, South Korean president Lee Myung-bak presided over a groundbreaking ceremony for a construction project between his country and the United Arab Emirates. At the time, the plant was the single biggest nuclear reactor deal in history.
But less than a decade later, Korea is dismantling its nuclear industry, shutting down older reactors and scrapping plans for new ones. State energy companies are being shifted toward renewables. What went wrong? Read the full story.
—Max S. Kim
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or tweet ’em at me.)
MIT Technology Review’s What’s Next series looks across industries, trends, and technologies to give you a first look at the future. You can read the rest of them here.
Thanks to the boom in artificial intelligence, the world of chips is on the cusp of a huge tidal shift. There is heightened demand for chips that can train AI models faster and ping them from devices like smartphones and satellites, enabling us to use these models without disclosing private data. Governments, tech giants, and startups alike are racing to carve out their slices of the growing semiconductor pie.
Here are four trends to look for in the year ahead that will define what the chips of the future will look like, who will make them, and which new technologies they’ll unlock.
CHIPS Acts around the world
On the outskirts of Phoenix, two of the world’s largest chip manufacturers, TSMC and Intel, are racing to construct campuses in the desert that they hope will become the seats of American chipmaking prowess. One thing the efforts have in common is their funding: in March, President Joe Biden announced $8.5 billion in direct federal funds and $11 billion in loans for Intel’s expansions around the country. Weeks later, another $6.6 billion was announced for TSMC.
The awards are just a portion of the US subsidies pouring into the chips industry via the $280 billion CHIPS and Science Act signed in 2022. The money means that any company with a foot in the semiconductor ecosystem is analyzing how to restructure its supply chains to benefit from the cash. While much of the money aims to boost American chip manufacturing, there’s room for other players to apply, from equipment makers to niche materials startups.
But the US is not the only country trying to onshore some of the chipmaking supply chain. Japan is spending $13 billion on its own equivalent to the CHIPS Act, Europe will be spending more than $47 billion, and earlier this year India announced a $15 billion effort to build local chip plants. The roots of this trend go all the way back to 2014, says Chris Miller, a professor at Tufts University and author of Chip War: The Fight for the World’s Most Critical Technology. That’s when China started offering massive subsidies to its chipmakers.
SIMON & SCHUSTER
“This created a dynamic in which other governments concluded they had no choice but to offer incentives or see firms shift manufacturing to China,” he says. That threat, coupled with the surge in AI, has led Western governments to fund alternatives. In the next year, this might have a snowball effect, with even more countries starting their own programs for fear of being left behind.
The money is unlikely to lead to brand-new chip competitors or fundamentally restructure who the biggest chip players are, Miller says. Instead, it will mostly incentivize dominant players like TSMC to establish roots in multiple countries. But funding alone won’t be enough to do that quickly—TSMC’s effort to build plants in Arizona has been mired in missed deadlines and labor disputes, and Intel has similarly failed to meet its promised deadlines. And it’s unclear whether, whenever the plants do come online, their equipment and labor force will be capable of the same level of advanced chipmaking that the companies maintain abroad.
“The supply chain will only shift slowly, over years and decades,” Miller says. “But it is shifting.”
More AI on the edge
Currently, most of our interactions with AI models like ChatGPT are done via the cloud. That means that when you ask GPT to pick out an outfit (or to be your boyfriend), your request pings OpenAI’s servers, prompting the model housed there to process it and draw conclusions (known as “inference”) before a response is sent back to you. Relying on the cloud has some drawbacks: it requires internet access, for one, and it also means some of your data is shared with the model maker.
That’s why there’s been a lot of interest and investment in edge computing for AI, where the process of pinging the AI model happens directly on your device, like a laptop or smartphone. With the industry increasingly working toward a future in which AI models know a lot about us (Sam Altman described his killer AI app to me as one that knows “absolutely everything about my whole life, every email, every conversation I’ve ever had”), there’s a demand for faster “edge” chips that can run models without sharing private data. These chips face different constraints from the ones in data centers: they typically have to be smaller, cheaper, and more energy efficient.
The US Department of Defense is funding a lot of research into fast, private edge computing. In March, its research wing, the Defense Advanced Research Projects Agency (DARPA), announced a partnership with chipmaker EnCharge AI to create an ultra-powerful edge computing chip used for AI inference. EnCharge AI is working to make a chip that enables enhanced privacy but can also operate on very little power. This will make it suitable for military applications like satellites and off-grid surveillance equipment. The company expects to ship the chips in 2025.
AI models will always rely on the cloud for some applications, but new investment and interest in improving edge computing could bring faster chips, and therefore more AI, to our everyday devices. If edge chips get small and cheap enough, we’re likely to see even more AI-driven “smart devices” in our homes and workplaces. Today, AI models are mostly constrained to data centers.
“A lot of the challenges that we see in the data center will be overcome,” says EnCharge AI cofounder Naveen Verma. “I expect to see a big focus on the edge. I think it’s going to be critical to getting AI at scale.”
Big Tech enters the chipmaking fray
In industries ranging from fast fashion to lawn care, companies are paying exorbitant amounts in computing costs to create and train AI models for their businesses. Examples include models that employees can use to scan and summarize documents, as well as externally facing technologies like virtual agents that can walk you through how to repair your broken fridge. That means demand for cloud computing to train those models is through the roof.
The companies providing the bulk of that computing power are Amazon, Microsoft, and Google. For years these tech giants have dreamed of increasing their profit margins by making chips for their data centers in-house rather than buying from companies like Nvidia, a giant with a near monopoly on the most advanced AI training chips and a value larger than the GDP of 183 countries.
Amazon started its effort in 2015, acquiring startup Annapurna Labs. Google moved next in 2018 with its own chips called TPUs. Microsoft launched its first AI chips in November, and Meta unveiled a new version of its own AI training chips in April.
AP PHOTO/ERIC RISBERG
That trend could tilt the scales away from Nvidia. But Nvidia doesn’t only play the role of rival in the eyes of Big Tech: regardless of their own in-house efforts, cloud giants still need its chips for their data centers. That’s partly because their own chipmaking efforts can’t fulfill all their needs, but it’s also because their customers expect to be able to use top-of-the-line Nvidia chips.
“This is really about giving the customers the choice,” says Rani Borkar, who leads hardware efforts at Microsoft Azure. She says she can’t envision a future in which Microsoft supplies all chips for its cloud services: “We will continue our strong partnerships and deploy chips from all the silicon partners that we work with.”
As cloud computing giants attempt to poach a bit of market share away from chipmakers, Nvidia is also attempting the converse. Last year the company started its own cloud service so customers can bypass Amazon, Google, or Microsoft and get computing time on Nvidia chips directly. As this dramatic struggle over market share unfolds, the coming year will be about whether customers see Big Tech’s chips as akin to Nvidia’s most advanced chips, or more like their little cousins.
Nvidia battles the startups
Despite Nvidia’s dominance, there is a wave of investment flowing toward startups that aim to outcompete it in certain slices of the chip market of the future. Those startups all promise faster AI training, but they have different ideas about which flashy computing technology will get them there, from quantum to photonics to reversible computation.
But Murat Onen, the 28-year-old founder of one such chip startup, Eva, which he spun out of his PhD work at MIT, is blunt about what it’s like to start a chip company right now.
“The king of the hill is Nvidia, and that’s the world that we live in,” he says.
Many of these companies, like SambaNova, Cerebras, and Graphcore, are trying to change the underlying architecture of chips. Imagine an AI accelerator chip as constantly having to shuffle data back and forth between different areas: a piece of information is stored in the memory zone but must move to the processing zone, where a calculation is made, and then be stored back to the memory zone for safekeeping. All that takes time and energy.
Making that process more efficient would deliver faster and cheaper AI training to customers, but only if the chipmaker has good enough software to allow the AI training company to seamlessly transition to the new chip. If the software transition is too clunky, model makers such as OpenAI, Anthropic, and Mistral are likely to stick with big-name chipmakers.That means companies taking this approach, like SambaNova, are spending a lot of their time not just on chip design but on software design too.
Onen is proposing changes one level deeper. Instead of traditional transistors, which have delivered greater efficiency over decades by getting smaller and smaller, he’s using a new component called a proton-gated transistor that he says Eva designed specifically for the mathematical needs of AI training. It allows devices to store and process data in the same place, saving time and computing energy. The idea of using such a component for AI inference dates back to the 1960s, but researchers could never figure out how to use it for AI training, in part because of a materials roadblock—it requires a material that can, among other qualities, precisely control conductivity at room temperature.
One day in the lab, “through optimizing these numbers, and getting very lucky, we got the material that we wanted,” Onen says. “All of a sudden, the device is not a science fair project.” That raised the possibility of using such a component at scale. After months of working to confirm that the data was correct, he founded Eva, and the work was published in Science.
But in a sector where so many founders have promised—and failed—to topple the dominance of the leading chipmakers, Onen frankly admits that it will be years before he’ll know if the design works as intended and if manufacturers will agree to produce it. Leading a company through that uncertainty, he says, requires flexibility and an appetite for skepticism from others.
“I think sometimes people feel too attached to their ideas, and then kind of feel insecure that if this goes away there won’t be anything next,” he says. “I don’t think I feel that way. I’m still looking for people to challenge us and say this is wrong.”
The global race for computational power is well underway, fueled by a worldwide boom in artificial intelligence. OpenAI’s Sam Altman is seeking to raise as much as $7 trillion for a chipmaking venture. Tech giants like Microsoft and Amazon are building AI chips of their own. The need for more computing horsepower to train and use AI models—fueling a quest for everything from cutting-edge chips to giant data sets—isn’t just a current source of geopolitical leverage (as with US curbs on chip exports to China). It is also shaping the way nations will grow and compete in the future, with governments from India to the UK developing national strategies and stockpiling Nvidia graphics processing units.
I believe it’s high time for America to have its own national compute strategy: an Apollo program for the age of AI.
In January, under President Biden’s executive order on AI, the National Science Foundation launched a pilot program for the National AI Research Resource (NAIRR), envisioned as a “shared research infrastructure” to provide AI computing power, access to open government and nongovernment data sets, and training resources to students and AI researchers.
The NAIRR pilot, while incredibly important, is just an initial step. The NAIRR Task Force’s final report, published last year, outlined an eventual $2.6 billion budget required to operate the NAIRR over six years. That’s far from enough—and even then, it remains to be seen if Congress will authorize the NAIRR beyond the pilot.
Meanwhile, much more needs to be done to expand the government’s access to computing power and to deploy AI in the nation’s service. Advanced computing is now core to the security and prosperity of our nation; we need it to optimize national intelligence, pursue scientific breakthroughs like fusion reactions, accelerate advanced materials discovery, ensure the cybersecurity of our financial markets and critical infrastructure, and more. The federal government played a pivotal role in enabling the last century’s major technological breakthroughs by providing the core research infrastructure, like particle accelerators for high-energy physics in the 1960s and supercomputing centers in the 1980s.
Now, with other nations around the world devoting sustained, ambitious government investment to high-performance AI computing, we can’t risk falling behind. It’s a race to power the most world-altering technology in human history.
First, more dedicated government AI supercomputers need to be built for an array of missions ranging from classified intelligence processing to advanced biological computing. In the modern era, computing capabilities and technical progress have proceeded in lockstep.
Over the past decade, the US has successfully pushed classic scientific computing into the exascale era with the Frontier, Aurora, and soon-to-arrive El Capitan machines—massive computers that can perform over a quintillion (a billion billion) operations per second. Over the next decade, the power of AI models is projected to increase by a factor of 1,000 to 10,000, and leading compute architectures may be capable of training a 500-trillion-parameter AI model in a week (for comparison, GPT-3 has 175 billion parameters). Supporting research at this scale will require more powerful and dedicated AI research infrastructure, significantly better algorithms, and more investment.
Although the US currently still has the lead in advanced computing, other countries are nearing parity and set on overtaking us. China, for example, aims to boost its aggregate computing power more than 50% by 2025, and it has been reported that the country plans to have 10 exascale systems by 2025. We cannot risk acting slowly.
Second, while some may argue for using existing commercial cloud platforms instead of building a high-performance federal computing infrastructure, I believe a hybrid model is necessary. Studies have shown significant long-term cost savings from using federal computing instead of commercial cloud services. In the near term, scaling up cloud computing offers quick, streamlined base-level access for projects—that’s the approach the NAIRR pilot is embracing, with contributions from both industry and federal agencies. In the long run, however, procuring and operating powerful government-owned AI supercomputers with a dedicated mission of supporting US public-sector needs will set the stage for a time when AI is much more ubiquitous and central to our national security and prosperity.
Such an expanded federal infrastructure can also benefit the public. The life cycle of the government’s computing clusters has traditionally been about seven years, after which new systems are built and old ones decommissioned. Inevitably, as newer cutting-edge GPUs emerge, hardware refreshes will phase out older supercomputers and chips, which can then be recycled for lower-intensity research and nonprofit use—thus adding cost-effective computing resources for civilian purposes. While universities and the private sector have driven most AI progress thus far, a fully distributed model will increasingly face computing constraints as demand soars. In a survey by MIT and the nonprofit US Council on Competitiveness of some of the biggest computing users in the country, 84% of respondents said they faced computation bottlenecks in running key programs. America will need big investments from the federal government to stay ahead.
Third, any national compute strategy must go hand in hand with a talent strategy. The government can better compete with the private sector for AI talent by offering workers an opportunity to tackle national security challenges using world-class computational infrastructure. To ensure that the nation has available a large and sophisticated workforce for these highly technical, specialized roles in developing and implementing AI, America must also recruit and retain the best global students. Crucial to this effort will be creating clear immigration pathways—for example, exempting PhD holders in relevant technical fields from the current H-1B visa cap. We’ll need the brightest minds to fundamentally reimagine how computation takes place and spearhead novel paradigms that can shape AI for the public good, push forward the technology’s boundaries, and deliver its gains to all.
America has long benefitted from its position as the global driver of innovation in advanced computing. Just as the Apollo program galvanized our country to win the space race, setting national ambitions for compute will not just bolster our AI competitiveness in the decades ahead but also drive R&D breakthroughs across practically all sectors with greater access. Advanced computing architecture can’t be erected overnight. Let’s start laying the groundwork now.
Eric Schmidt was the CEO of Google from 2001 to 2011. In 2024, Eric & Wendy co-founded Schmidt Sciences, a philanthropic venture to fund unconventional areas of exploration in science & tech.








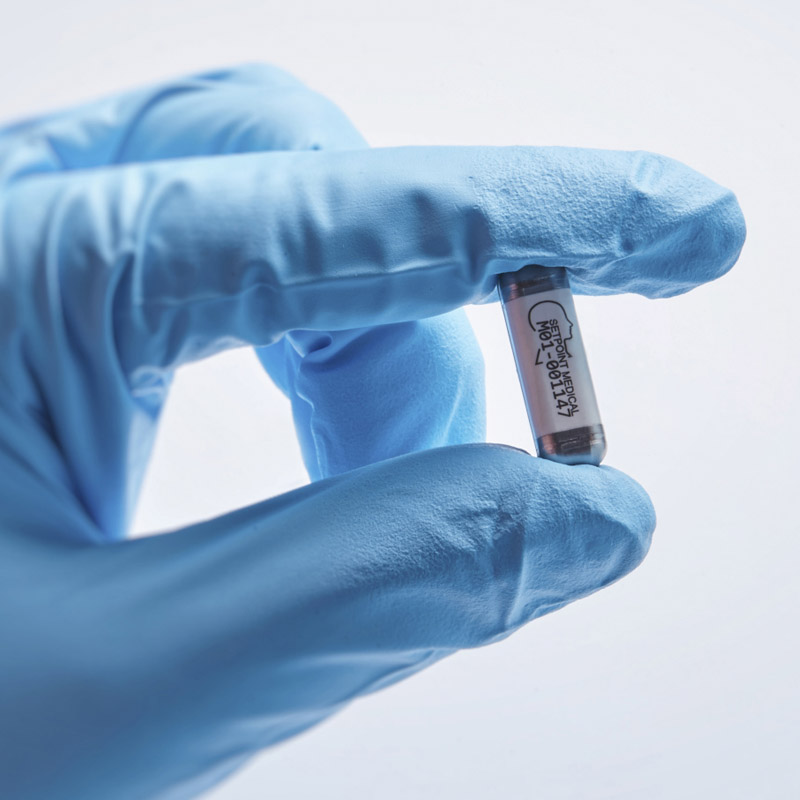
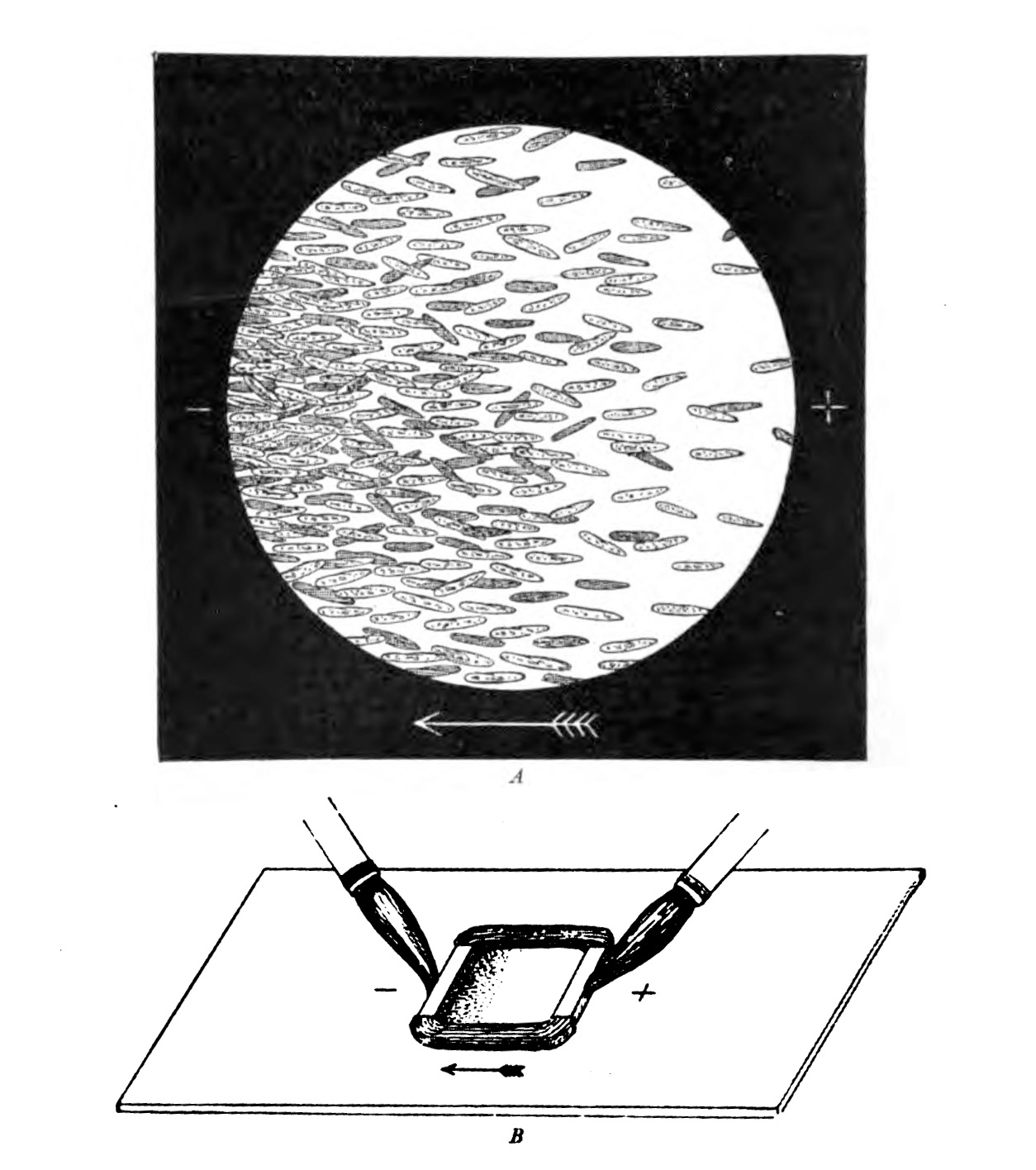








































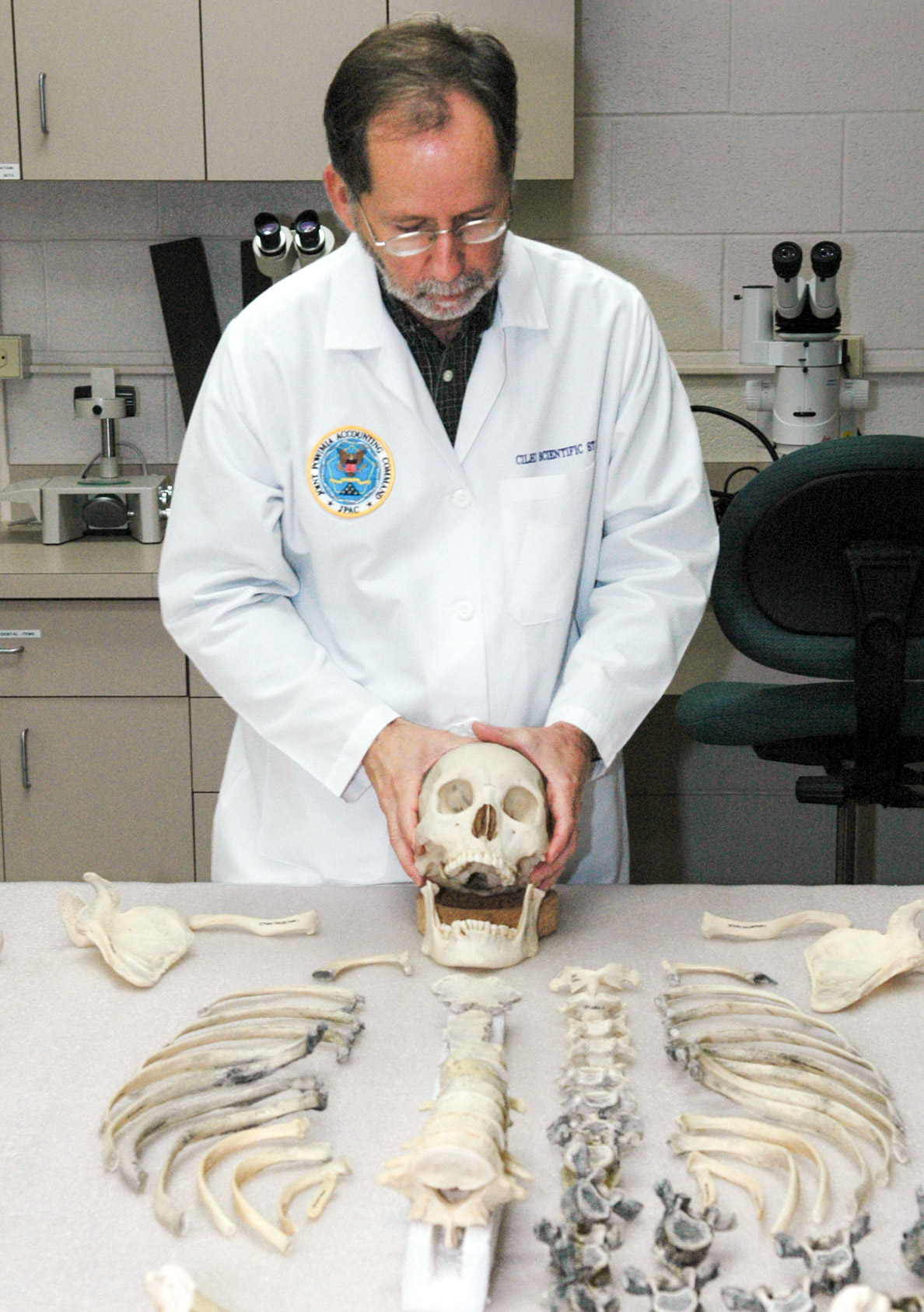













 i almost chucked the thing i stg
i almost chucked the thing i stg



